
设计一个缓存系统,不得不要考虑的问题就是:缓存穿透、缓存击穿与失效时的雪崩效应。
缓存穿透
是指当用户在查询一条数据的时候,而此时数据库和缓存却没有关于这条数据的任何记录, 而这条数据在缓存中没找到就会向数据库请求获取数据。它拿不到数据时,是会一直查询数据库, 这样会对数据库的访问造成很大的压力。
缓存空对象
即便数据库中不存在,也将这个key放在缓存中,value为null,这样也可以避免频繁查询数据库, 实现比较简单。
布隆过滤器
是一种基于概率的数据结构,主要使用爱判断当前某个元素是否在该集合中,运行速度快。 我们也可以简单理解为是一个不怎么精确的 set 结构(set 具有去重的效果)。但是有个小问题: 当你使用它的 contains 方法去判断某个对象是否存在时,它可能会误判。 也就是说布隆过滤器不是特别精确,但是只要参数设置的合理,它的精确度可以控制的相对足够精确, 只会有小小的误判概率(这是可以接受的)。当布隆过滤器说某个值存在时,这个值可能不存在; 当它说不存在时,那就肯定不存在。
那布隆过滤器到底有什么特点呢:
- 一个非常大的二进制位数组(数组中只存在 0 和 1)
- 拥有若干个哈希函数(Hash Function)
- 在空间效率和查询效率都非常高
- 布隆过滤器不会提供删除方法,在代码维护上比较困难。
每个布隆过滤器对应到 Redis 的数据结构里面就是一个大型的位数组和几个不一样的无偏 hash 函数。 所谓无偏就是能够把元素的 hash 值算得比较均匀。
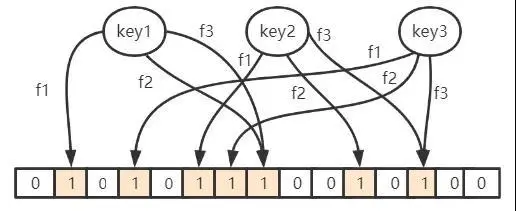
当 key1 和 key2 映射到位数组上的位置为 1 时,假设这时候来了个 key8,要查询是不是在里面, 恰好 key8 对应位置也映射到了这之间,那么布隆过滤器会认为它是存在的,这时候就会产生误判 (因为明明 key8 是不在的)。
提高布隆过滤器的准确率呢?要提高布隆过滤器的准确率,就要说到影响它的三个重要因素:
- 哈希函数的好坏:hash函数的设计也是一个十分重要的问题,对于好的hash函数能大大降低布隆过滤器的误判率。
- 存储空间大小:如果其位数组越大的话,那么每个key通过hash函数映射的位置会变得稀疏许多,不会那么紧凑,有利于提高布隆过滤器的准确率。
- 哈希函数个数:如果key通过许多hash函数映射,那么在位数组上就会有许多位置有标志,这样当用户查询的时候,在通过布隆过滤器来找的时候,误判率也会相应降低。
缓存击穿
缓存击穿是指,短时间内大量请求一个缓存中不存在的数据,有两种场景可能导致这种情况:
- 一个“冷门”key,突然被大量用户请求访问。
- 一个“热门”key,在缓存中时间恰好过期,这时有大量用户来进行访问。
加锁
对于缓存击穿的问题:我们常用的解决方案是加锁。 这时只能让第一个请求进行查询数据库, 然后把从数据库中查询到的值存储到缓存中,对于剩下的相同的key,可以直接从缓存中获取即可。
- 在单机环境下:直接使用常用的锁即可(如:Lock、Synchronized等)
- 分布式环境下:使用分布式锁,如:基于数据库、基于Redis或者zookeeper 的分布式锁
缓存雪崩
缓存雪崩是指在某一个时间段内,缓存集中过期失效,如果这个时间段内有大量请求, 而查询数据量巨大,所有的请求都会达到存储层,存储层的调用量会暴增,引起数据库压力过大甚至宕机。
可能导致雪崩的原因:
- Redis突然宕机
- 大部分数据失效
redis高可用
redis有可能挂掉,多增加几台redis实例,(一主多从或者多主多从), 这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍, 这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key。
限流降级
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量, 对某个key只允许一个线程查询数据和写缓存,其他线程等待。
不同的过期时间
设置不同的过期时间,缓存失效的时间点尽量均匀。
参考资料
文档信息
- 本文作者:Bob.Zhu
- 本文链接:https://adolphor.github.io/2020/08/31/cache-penetration-breakdown-avalanche/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)