
概念
当计算算法的时间时,数据元素个数不一样的时候,会发生不同的变化,有些线性变化,有些指数变化,所以我 们需要的是一个可以描述算法的速度是如何与数据项的个数相联系的比较,一种快捷的方法来评价计算机算法的效率。
表示方法
在计算机科学中,这种粗略的度量方法被称作”大O”表示法,大O表示法使用大写字母O,可以认为其含义是”order of”(大约是)。
假定操作一个元素所需的时间是常数 K,那么我们比较算法A和算法B速度 的时候,会说算法A是算法B的多少倍,那么这个常数K分子分母同时约去,那么就可以直接忽略K 的具体值的大小。也就是说,当比较算法时,并不在乎具体的微处理器芯片或编译器操作一个元素 所需要的时间,真正需要比较的是对应不同的 N 值,T 是如何变化的,而不是具体的数字,因此 不需要常数。 那么我们需要的是这样一个表达式,可以表达 T = fun(N) 之间的关系,且常数可以直接忽略。
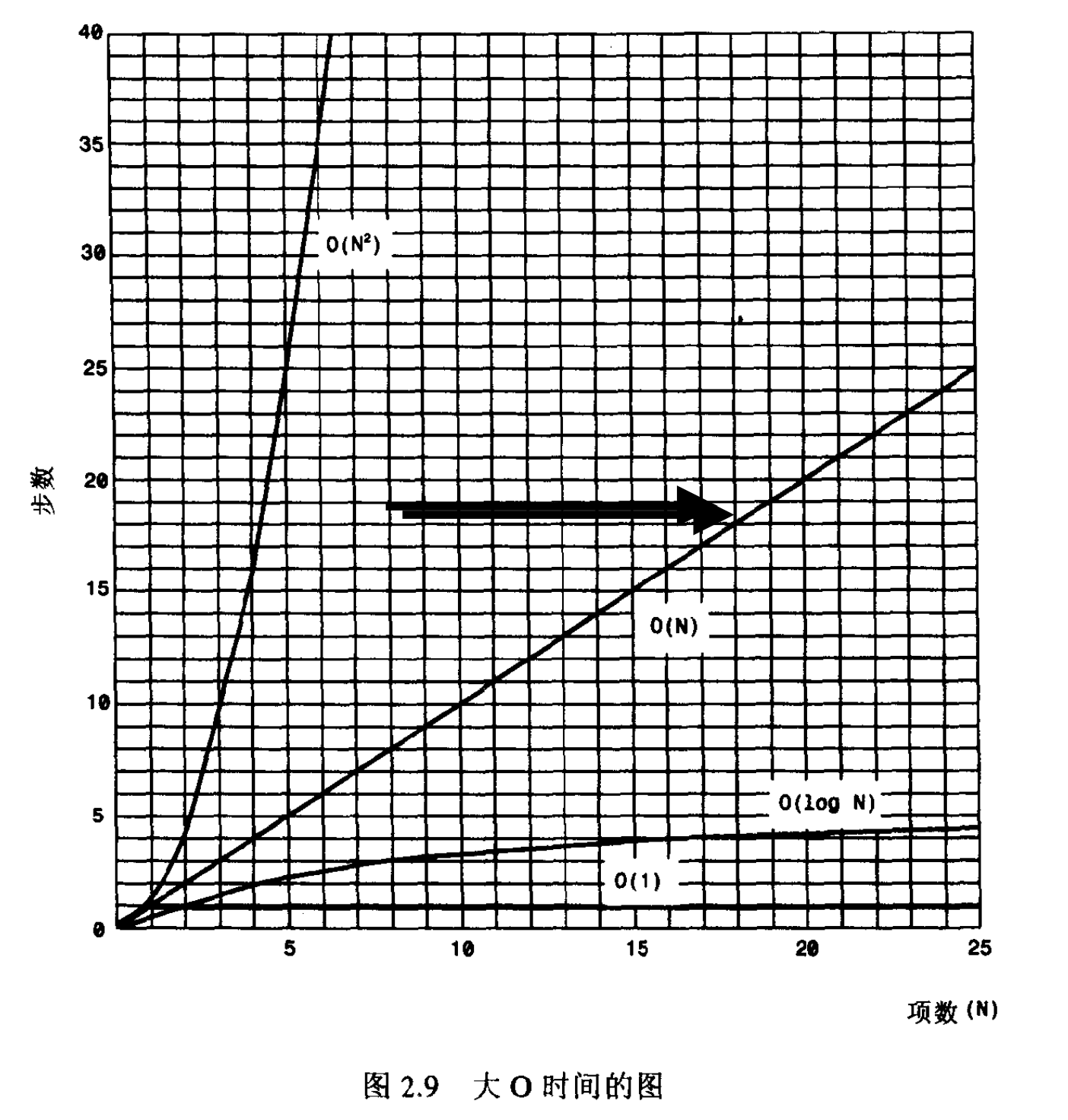
O(1)
不管有多少元素,所需时间都是操作一个元素所需要的时间 K,比如,在数组末尾增加一个元素。 所以,将常数 K 忽略之后,就是 O (1)
O(N)
所有时间与元素个数N线性正相关,比如,有序数组中查找一个数据,如果需要查找的元素位于首位, 所需时间是K,如果需要查找的元素位于末尾,那么所需时间是 N * K,大量测试平均下来的时间就是 T = N * K/2,把2这个常数并入到常数K中,也就是 T = N * K,那么使用大O表示法就是 O (N)
O(log N)
同样,可以为二分查找制定出一个与 T 和 N 有关的公式:T = K * log2(N)。正如前面所提到的, 时间 T 与以2为底 N 的对数成正比。实际上,由于所有对数都和其他对数成正比(从底数为2转换为 底数为10需乘以3.322),我们可以将这个为常数的底数也并入 K,由此不必指定底数: T = K * log(N)
如何计算
多步骤复杂度相加
复杂度本身直接比较数量级就行了,相同数量级相加之后还是当前数量级的复杂度,不同数量级相加可以 直接取较高数量级的复杂度。比如:O(1)+O(N)=O(N),O(N)+O(logN)=O(N)
1~N之间的可能值取最大值为N
如果一个元素依次比较,可能第一就比较成功,也可能最后一步N才成功,那么就需要取最坏情况下的N作为复杂度数量
两次循环的复杂度
如果操作的时候,第一需要N步,第二次需要N-1步,依次递减,最后只需要1步,可以得出需要的步骤数为 (N-1)+(N-2)+(N-3)+...+1=N*(N-1)/2,忽略常数1,约等价于于 N*N/2,忽略常数2,等价于O(N^2), 那么最终的时间复杂度就是 O(N^2),具体详见普通排序-冒泡排序
常用算法汇总
| 算法名称 | 插入 | 查找 | 删除 | 修改 |
|---|---|---|---|---|
| 无序数组(固定长度) | O (1) | O (N) | O (1) | O (1) |
| 无序数组(动态调整长度) | O(1)+O(N)=O(N) | O(N) | O(N)+O(N)=O(N) | O(N) |
| 有序数组 | O(logN)+O(N)=O(N) | O(logN) | O(logN)+O(N)=O(N) | O(N)+O(logN)=O(N) |
参考资料
文档信息
- 本文作者:Bob.Zhu
- 本文链接:https://adolphor.github.io/2021/03/30/01-time-complexity/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)