
概念
一句话简单来说,索引的出现其实就是为了提高数据查询的效率,就像书的目录一样。
索引模型
索引的出现是为了提高查询效率,但是实现索引的方式却有很多种,所以这里也就引入了索引模型的概念。 可以用于提高读写效率的数据结构很多,这里我先给你介绍三种常见、也比较简单的数据结构,它们分别是 哈希表、有序数组和搜索树。
哈希表
哈希表是一种以键 - 值(key-value)存储数据的结构,我们只要输入待查找的键即 key,就可以找到 其对应的值即 Value。哈希的思路很简单,把值放在数组里,用一个哈希函数把 key 换算成一个确定的 位置,然后把 value 放在数组的这个位置。 不可避免地,多个 key 值经过哈希函数的换算,会出现同 一个值的情况。处理这种情况的一种方法是,拉出一个链表。(Bob:其实,对于哈希碰撞,有多种解决方 案,比如 再开放地址法、再哈希法、链地址法)
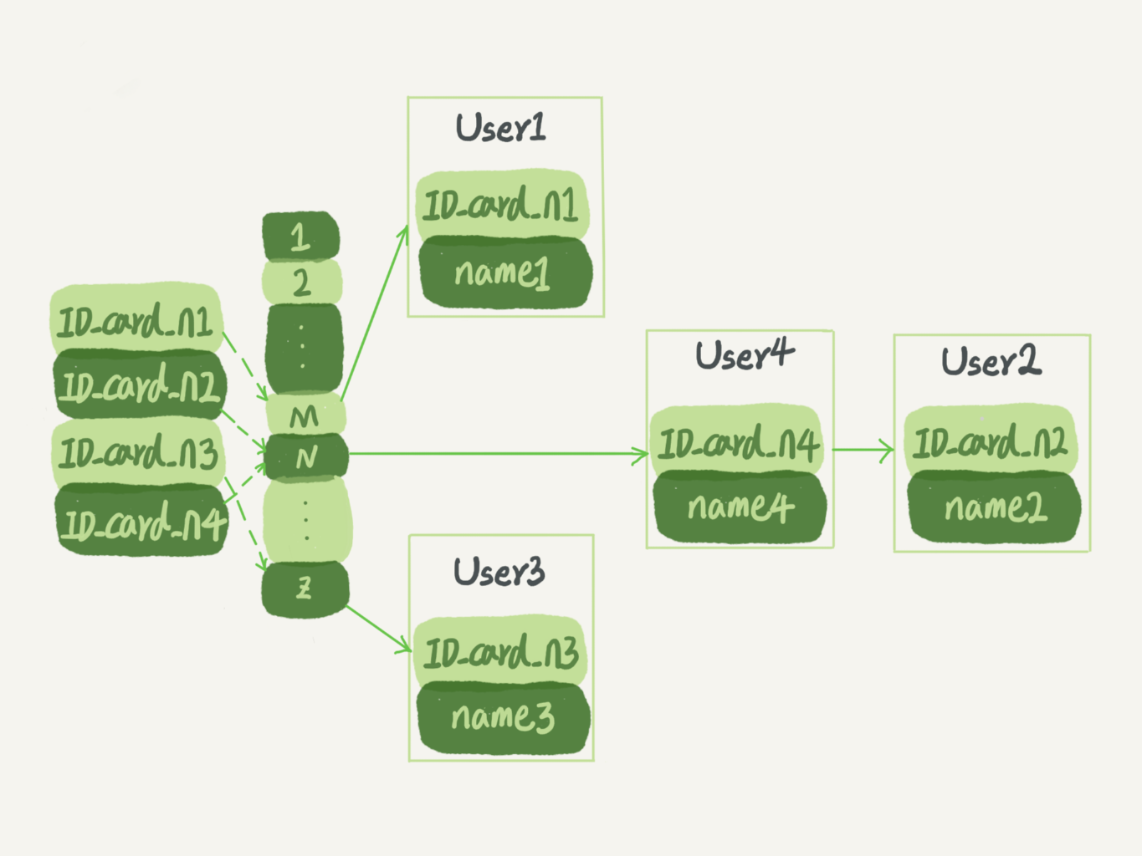
图中,User2 和 User4 根据身份证号算出来的值都是 N,但没关系,后面还跟了一个链表。假设,这时候 你要查 ID_card_n2 对应的名字是什么,处理步骤就是:首先,将 ID_card_n2 通过哈希函数算出 N; 然后,按顺序遍历,找到 User2。
需要注意的是,图中四个 ID_card_n 的值并不是递增的,这样做的好处是增加新的 User 时速度会很快, 只需要往后追加。但缺点是,因为不是有序的,所以哈希索引做区间查询的速度是很慢的。 你可以设想下,如 果你现在要找身份证号在[ID_card_X, ID_card_Y]这个区间的所有用户,就必须全部扫 描一遍了。 所以, 哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。
使用哈希表索引有以下一些限制:
- 哈希索引数据不是按照索引值顺序存储的,无法用于排序。
- 哈希索引不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的。 例如在数据列(a,b)上建立哈希索引,如果查询的列只有a就无法使用该索引。
- 哈希索引只支持等值比较查询,不支持任何范围查询。
有序数组
有序数组在等值查询和范围查询场景中的性能就都非常优秀。还是上面这个根据身份证号查名字的例子,如果我 们使用有序数组来实现的话,示意图如下所示:
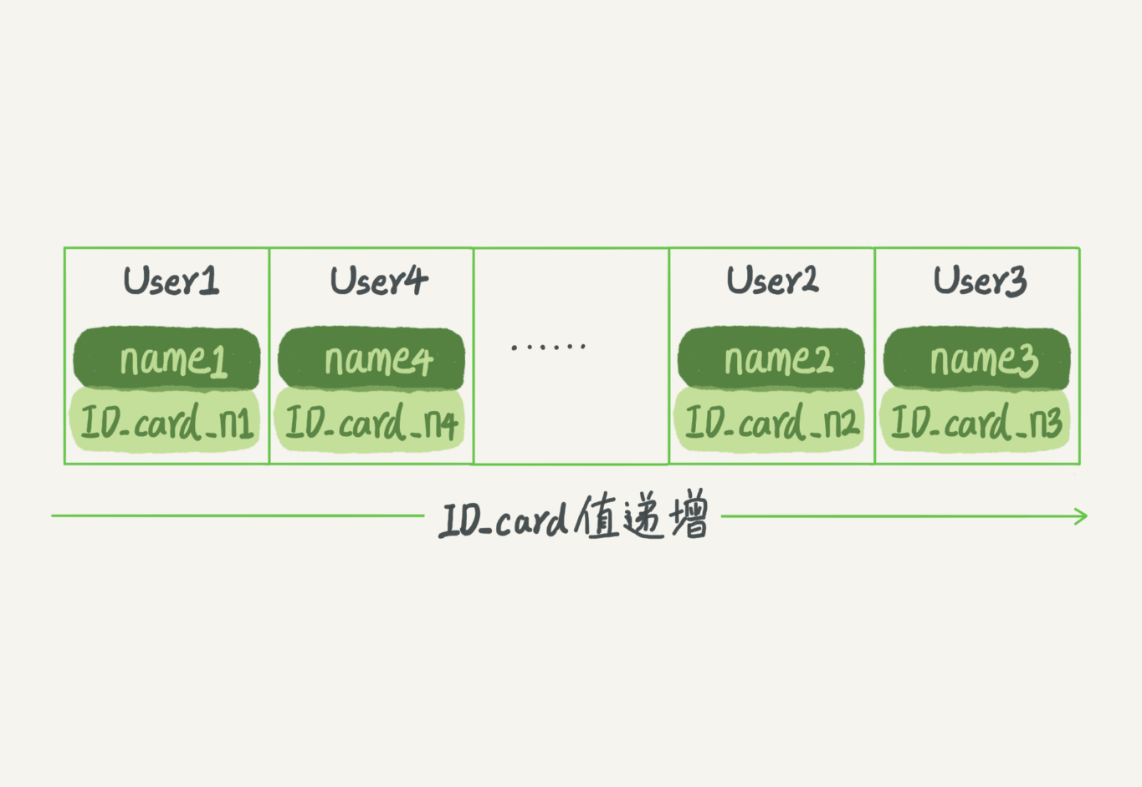
这里我们假设身份证号没有重复,这个数组就是按照身份证号递增的顺序保存的。这时候如果你要查 ID_card_n2 对应的名字,用二分法就可以快速得到,这个时间复杂度是 O(log(N))。 同时很显然,这个索引结构支持范围查询。 你要查身份证号在[ID_card_X, ID_card_Y]区间的 User,可以先用二分法找到 ID_card_X(如果不存在 ID_card_X,就找到大于 ID_card_X 的第一个 User),然后向右遍历,直到查到第一个大于 ID_card_Y 的身份 证号,退出循环。 如果仅仅看查询效率,有序数组就是最好的数据结构了。但是,在需要更新数据的时候就麻烦了,你 往中间插入一个记录就必须得挪动后面所有的记录,成本太高。 所以,有序数组索引只适用于静态存储引擎,比如你要 保存的是 2017 年某个城市的所有人口信息,这类不会再修改的数据。
B-Tree索引
二叉搜索树也是课本里的经典数据结构了。还是上面根据身份证号查名字的例子,如果我们用二叉搜索树来实现的话,示 意图如下所示:
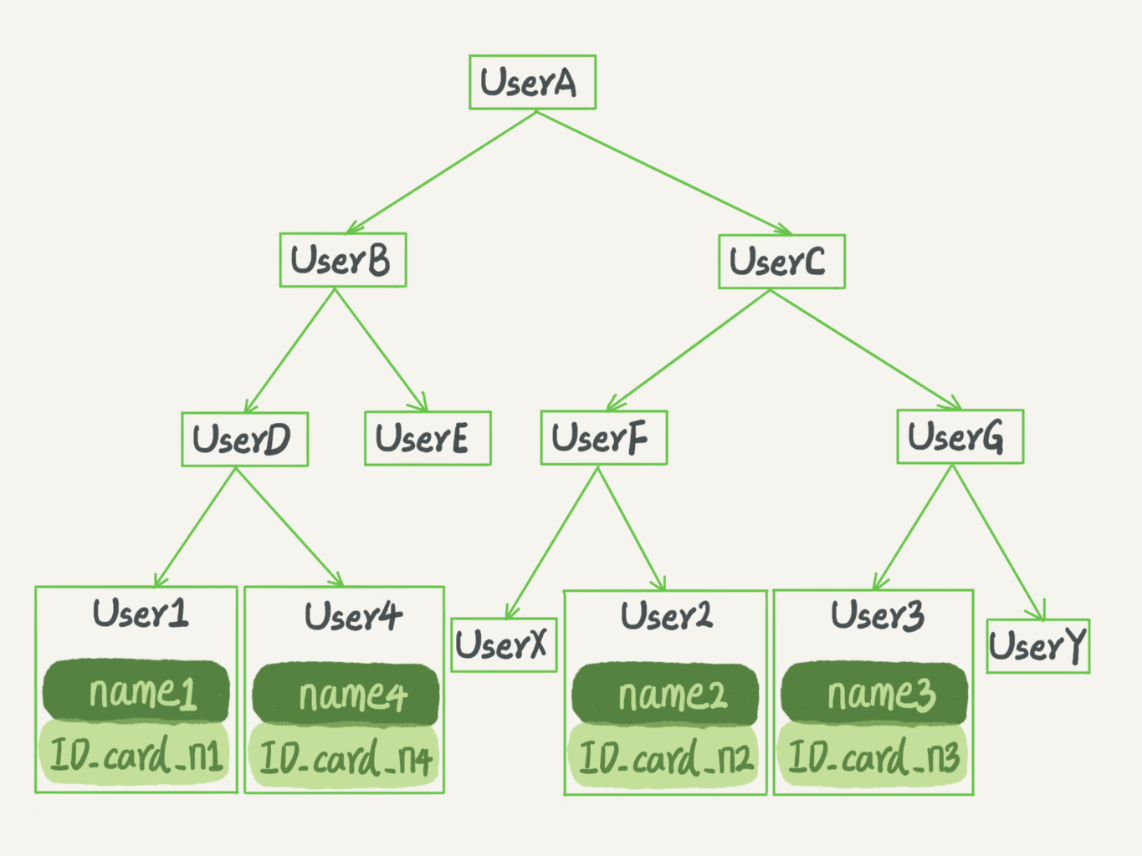
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且同层级的节点间有指针相互链接。
空间索引
MyISAM 表支持空间索引,可以用作地理数据存储。和 B-Tree 索引不同,这类索引无需前缀查询。空间 索引会从所有维度来索引数据,查询时可以有效地使用任意维度来组合查询。必须使用 MySQL 的 GIS 即 地理信息系统的相关函数来维护数据,但 MySQL 对 GIS 的支持并不完善,因此大部分人都不会使用这个特性。
全文索引
通过数值比较、范围过滤等就可以完成绝大多数需要的查询,但如果希望通过关键字匹配进行查询,就需要 基于相似度的查询,而不是精确的数值比较,全文索引就是为这种场景设计的。
MyISAM 的全文索引是一种特殊的 B-Tree 索引,一共有两层。第一层是所有关键字,然后对于每一个关 键字的第二层,包含的是一组相关的”文档指针”。全文索引不会索引文档对象中的所有词语,它会根据规则 过滤掉一些词语,例如停用词列表中的词都不会被索引。
InnoDB 的索引模型
为什么 MySQL 会选择 B+ 树做为其索引模型呢?其他的数据结构不行吗?
为什么选 B+树
在MySQL查询中,最常用的一个是等值查询,一个是范围查询。哈希表不支持范围查询,有序数组的时间复杂度 是N,而二叉树及其变种的时间复杂度是log(N),所以排序哈希表和有序数组的使用。下面重点分析几种树:
- 二叉树
- 二叉树
- 二叉树失衡的情况下,会退化为链表
- 平衡二叉树(AVL树)
- 完全保持平衡的树,所有节点的左右子树高度差的绝对值不超过1
- 修改和删除的时候效率较低
- 红黑树
- 是一棵二叉树
- 近乎完全平衡(路径上黑色节点的数量相同)
- 具有稳定的时间复杂度O(nlogN)
- 二叉树
- N叉树
- B树
- 树内的每个节点都存储数据
- 叶子节点之间无指针相邻
- B+树
- 数据只出现在叶子节点
- 所有叶子节点增加了一个链指针
- B树
上面说的是各种树的数据结构,如果是在内存中操作,那么各种树基本上都能满足需求。但是,数据库一般是 存储在硬盘中,那么就需要配合考虑磁盘IO情况,因为在内存中性能相似的数据库结构,在磁盘IO中会有较大 的性能差异。
对于二叉树,磁盘中操作会有以下几个问题:
- 数据非常大时, 树高度会很高, 造成磁盘io扫描次数很高
- 一个节点只是存放一个数据, 数据与数据之间在物理内存相隔甚远, 磁盘扫描需要频繁转动
- 需要频繁的从磁盘读数据到内存中, 即使操作系统有预读, 但是带出来的大多是暂时用不上的无用数据, 造成浪费
鉴于以上几个问题, 有以下几点需要优化的:
- 减少磁盘io扫描次数
- 减少磁盘io转动频率
- 利用好操作系统的预读, 局部性原理
b树的出现就是为了解决以上问题(但并不是全部问题) 从以上b树的特点知道了, b树是N叉树, 层高大大降低, 因此可以减少磁盘io的扫描次数, 并且b树每个节点不是以一个数据为单位, 而是以页, 每个节点就是操作系统 的一个页的大小, 因此可以存放更多的数据. 较好的利用操作系统预读, 局部性原理的特点, 每次从磁盘读出 一个页, 然后再来查询.
由于b树所有的节点都可能包含目标数据,总是要从根节点向下遍历子树查找满足条件的数据行,这个特点带来 了大量的随机 I/O,也是b树最大的性能问题.
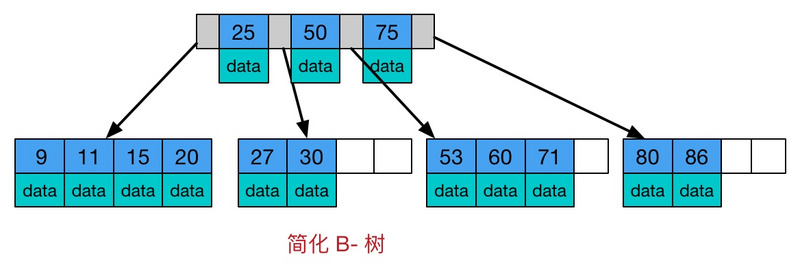
但是, 在mysql的innodb中为什么不选用b树呢? 并不是b树不好, 而是有比他更合适的 B+树:
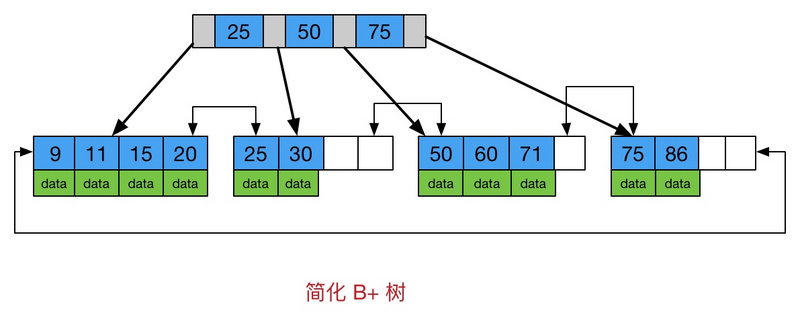
b+树拥有b树的所有优点, 并且b+树的非叶子节点不存放数据, 而是单单存放索引, 只有在叶子节点存放 索引+数据, 并且叶子节点通过前后指针构成双向链表的结构, 因此通过树结构定位到索引后, 可以通叶子节点 的链表指针很快的直接遍历得到范围查询的结果 这样更好的利用了顺序io比随机io性能更高的优化. 这个特点 是b树不具备的.
对于索引在磁盘中的存储,可以参考这个图片:
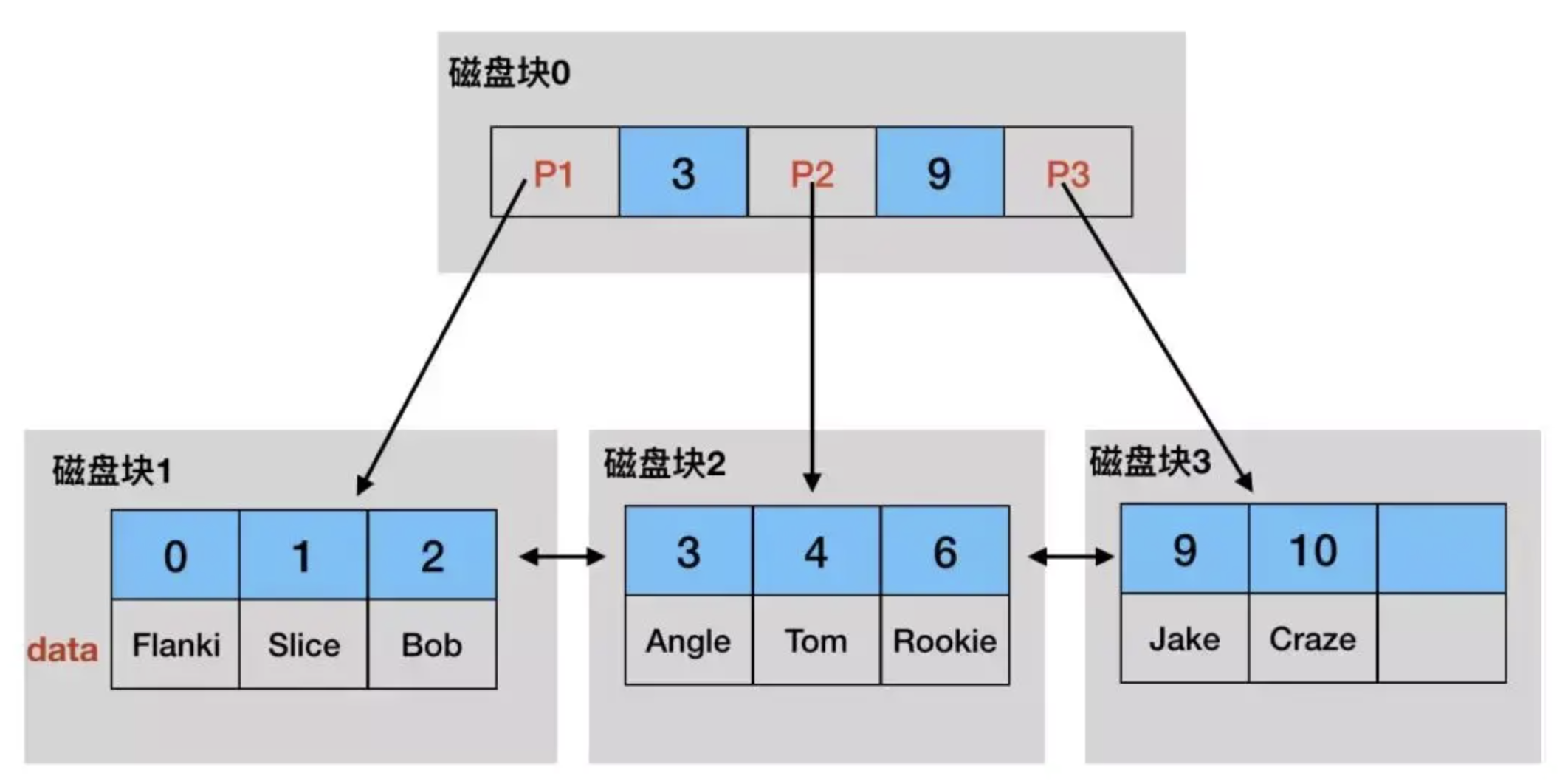
- B+树索引并不能直接找到行,只是找到行所在的页,通过把整页读入内存,再在内存中查找。
- 索引的B+树高度一般为2-4层,查找记录时最多只需要2-4次IO。
B+树特点:
- 【B+ 树的层级更少】:相较于 B 树,B+ 树每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快。
- 【B+ 树查询速度更稳定】:B+ 树所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比 B 树更稳定。
- 【B+ 树天然具备排序功能】:B+ 树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比 B 树高。
- 【B+ 树全节点遍历更快】:B+ 树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像 B 树对每一层进行遍历,这有利于数据库做全表扫描。
- B 树相对于 B+ 树的优点:如果经常访问的数据离根节点很近,而 B 树的非叶子节点本身存有关键字其数据的地址,此种数据检索的时候会要比 B+ 树快。
主键索引(聚簇索引)
主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
聚簇索引不是一种索引类型,而是一种数据存储方式。InnoDB 的聚簇索引实际上在同一个结构中保存了 B-Tree 索引和数据行。当表有聚餐索引时,它的行数据实际上存放在索引的叶子⻚中,因为无法同时把 数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
优点:
- 可以把相关数据保存在一起。
- 数据访问更快,聚簇索引将索引和数据保存在同一个 B-Tree 中,因此获取数据比非聚簇索引要更快。
- 使用覆盖索引扫描的查询可以直接使用⻚节点中的主键值。
缺点:
- 聚簇索引最大限度提高了 IO 密集型应用的性能,如果数据全部在内存中将会失去优势。
- 更新聚簇索引列的代价很高,因为会强制每个被更新的行移动到新位置。
- 基于聚簇索引的表插入新行或主键被更新导致行移动时,可能导致⻚分裂,表会占用更多磁盘空间可能导致⻚分裂,表会占用更多磁盘空间。
- 当行稀疏或由于⻚分裂导致数据存储不连续时,全表扫描可能很慢。
非主键索引
非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
回表
因为InnoDB采用的B+树作为索引,主键索引的子节点以及非主键索引的叶子节点内容都只是主键的值, 不包含具体数据行,那么根据非主键索引检索到的数据只是主键ID,那么再查询的时候就需要根据这个ID 再去数据库中根据主键索引查询一次这个主键对应的数据行,这个过程就叫做回表。
如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树; 如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500, 再到 ID 索引树搜索一次。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
但是,不使用主键查询就一定会产生回表操作吗?答案是NO,如果是覆盖索引的情况,也可以避免回表, 详见下面的覆盖索引部分。
需要注意点的是,在使用explain关键字查看执行计划的时候,extra信息稍有不同:
- id,不需要回表,无信息,主键索引无论如何都不会回表,所以不需要特殊说明
- 普通索引,需要回表,无信息,普通索引一般都进行回表,所以如果回表了说明是常规流程,不需要特殊说明
- 覆盖索引,不需要回表,Extra 显示 Using index,表示使用了覆盖索引不需要回表,需要特殊说明
覆盖索引
覆盖索引指一个索引包含或覆盖了所有需要查询的字段的值,不再需要根据索引回表查询数据。
常见的实现覆盖索引的方法是:将被查询的字段,建立到联合索引里去,如上面的 people_first_name_last_name_age_index 索引。 explain分析: explain select first_name,last_name,age from people where first_name='Bob'; Extra 显示 Using index,说明虽然 first_name 是普通联合索引, 但是因为需要查询的字段信息全部都可以从索引中直接获取,通过一次扫描B+树即可查询到相应的结果, 这样就实现了覆盖索引。
联合索引
上面说到,为了避免回表,可以通过创建联合索引来实现。其实,联合索引不仅可以在查询的时候避免回表, 还可以使用联合索引进行索引下推,提高查询效率。
索引下推
索引下推一般是在联合索引,且是范围查询的时候起作用。使用 explain 查看执行计划,如果 Extra 信息中显示了 “Using index condition“,则说明使用了索引下推。
explain select * from people where first_name='Bob' and age>18;
创建一个 first_name 和 age 的联合索引,那么上述的SQL的执行逻辑在没有索引下推的情况执行如下:
- 存储引擎根据索引查找出 age>18 的用户id,分别是:1,5,7
- 存储引擎到表格中取出id in (1,5,7)的3条记录,返回给服务层
- 服务层过滤掉不符合birthday=”03-01”条件的记录,最后返回查询结果为id=4的1行记录。
如果开启了索引下推优化,执行步骤如下:
- 存储引擎根据索引查找出age>20的用户id,并使用索引中的first_name字段过滤掉不符合first_name=’Bob’条件的记录
- 存储引擎到表格中取出id=4的1条记录,返回给服务层;
- 最后返回查询结果为id=4的1行记录。
启用索引下推后,把where条件由MySQL服务层放到了存储引擎层去执行,带来的好处就是存储引擎根据 id 到表格中读取数据的次数变少了。在上面这个例子中,没有索引下推时需要多回表查询2次。并且回表查询 很可能是离散IO,在某些情况下,对数据库性能会有较大提升。
左前缀匹配
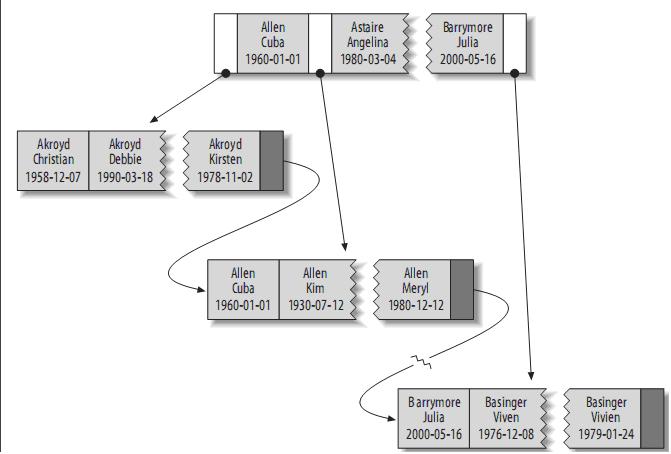
可以利用B-Tree索引进行全关键字、关键字范围和关键字前缀查询,当然,如果想使用索引,你必须保证 按索引的最左边前缀(leftmost prefix of the index)来进行查询:
- 匹配全值(Match the full value):对索引中的所有列都指定具体的值
- 匹配最左前缀(Match a leftmost prefix):你可以利用索引查找last name为Allen的人,仅仅使用索引中的第1列。
- 匹配列前缀(Match a column prefix):例如,你可以利用索引查找last name以J开始的人,这仅仅使用索引中的第1列。
- 匹配值的范围查询(Match a range of values):可以利用索引查找last name在Allen和Barrymore之间的人,仅仅使用索引中第1列。
- 匹配部分精确而其它部分进行范围匹配(Match one part exactly and match a range on another part):可以利用索引查找last name为Allen,而first name以字母K开始的人。
- 仅对索引进行查询(Index-only queries):如果查询的列都位于索引中,则不需要读取元组的值(覆盖索引)。
使用B-tree索引有以下一些限制:
- 查询必须从索引的最左边的列开始,否则无法使用索引。关于这点已经提了很多遍了。例如你不能利用索引查找在某一天出生的人。
- 不能跳过某一索引列。例如,你不能利用索引查找last name为Smith且出生于某一天的人。
- 存储引擎不能使用索引中范围条件右边的列。例如,如果你的查询语句为WHERE last_name=”Smith” AND first_name LIKE ‘J%’ AND dob=’1976-12-23’,则该查询只会使用索引中的前两列,因为LIKE是范围查询
索引使用原则
- 建立索引:查询频次较高数据创建索引
- 使用前缀索引
- 选择合适的索引顺序
- 删除无用索引
TODO
- 为什么表数据删掉一半,表大小不变?
- 关于mysql 删除数据后物理空间未释放(转载) 索引信息中的列的信息说明
- mysql删除操作其实是假删除
参考资料
文档信息
- 本文作者:Bob.Zhu
- 本文链接:https://adolphor.github.io/2021/05/20/mysql-index/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)