
许多硬件部件都有这样一个特点 —— 硬件设计者引人一个部件是为了解决某些问题,然而这些部件自身又会 引人新的问题。为了解决这些新的问题,硬件设计者又引入了其他部件。因此,掌握这些部件之间的这种关系 有助于我们更好地理解相关部件。Java内存模型是对Java多线程程序的正确性进行推理的理论基础,了解 Java内存模型有助于编写正确的多线程程序以及进行代码复审。
高速缓存
现代处理器处理能力的提升要远胜于主内存(DRAM)访问速率的提升,主内存执行一次内存读、写操作所需的 时间可能足够处理器执行上百条的指令。为了弥补处理器与主内存处理能力之间的鸿沟,硬件设计者在主内存 和处理器之间引人了高速缓存( Cache ), 如图11-1 所示。
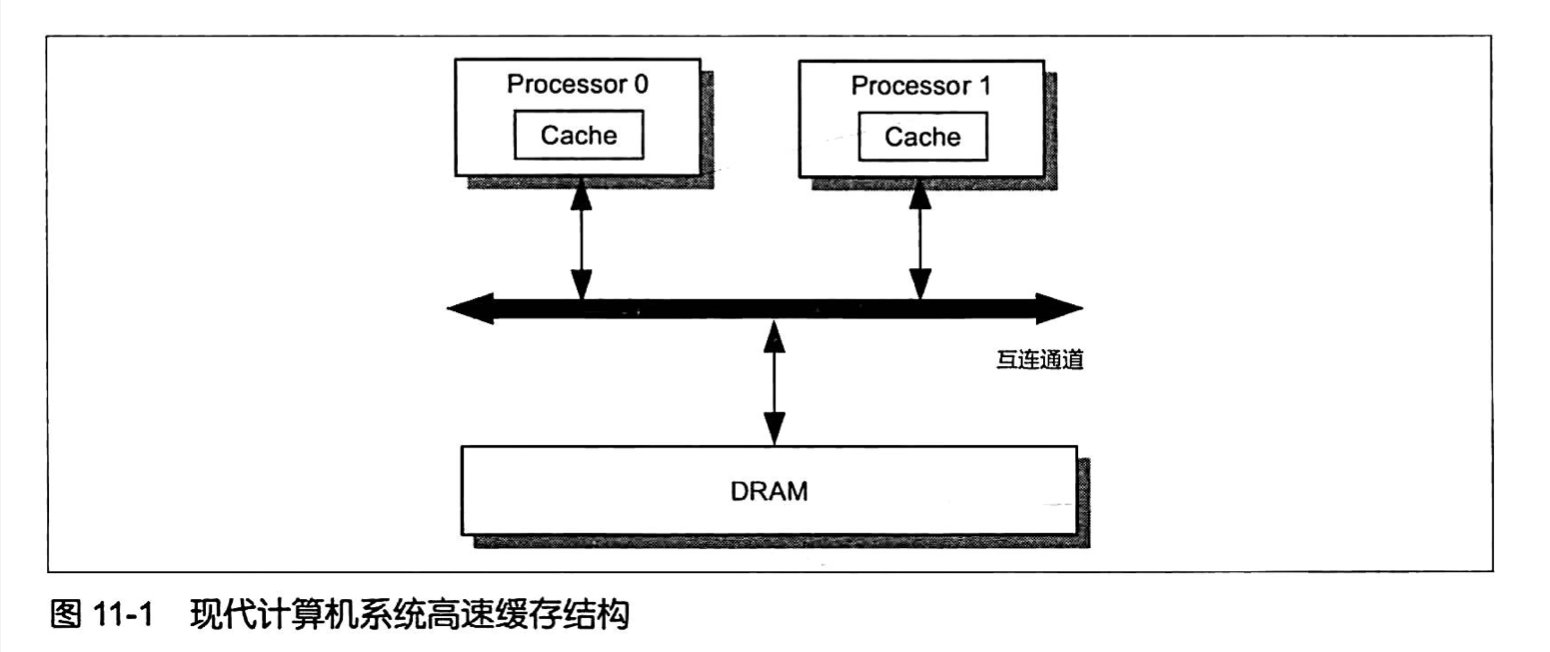
高速缓存是一种存取速率远比主内存大而容量远比主内存小的存储部件,每个处理器都有其高速缓存。引入 高速缓存之后,处理器在执行内存读、写操作的时候并不直接与主内存打交道,而是通过高速缓存进行的。 变量名相当于内存地址,而变量值则相当于相应内存空间所存储的数据。从这个角度来看,高速缓存相当于 为程序所访问的每个变量保留了一份相应内存空间所存储数据(变量值)的副本。由于高速缓存的存储容量 远小于主内存,因此高速缓存并不是每时每刻保留着所有变量值的副本。高速缓存相当于一个由硬件实现的 容量极小的散列表(HashTable),其键(Key)是一个内存地址,其值(Value)是内存数据的副本或者准备 写人内存的数据。从内部结构来看,高速缓存相当于一个拉链散列表( Chained Hash Table),它包含 若干桶( Bucket,硬件上称之为Set),每个桶又可以包含若干缓存条目( Cache Entry),如图11-2 所示。
处理器在执行内存访问操作时会将相应的内存地址解码2。内存地址的解码结果包括 tag、index 以及 offset 这三部分数据。其中,index 相当于桶编号,它可以用来定位内存地址对应的桶;一个桶可能 包含多个缓存条目,tag 相当于缓存条目的相对编号,其作用在于用来与同一个桶中的各个缓存条目中的Tag 部分进行比较,以定位-一个具体的缓存条目;一个缓存条目中的缓存行可以用来存储多个变量,offset 是缓存行内的位置偏移,其作用在于确定一个变量在一个缓存行中的存储起始位置。根据这个内存地址的 解码结果,如果高速缓存子系统能够找到相应的缓存行并且缓存行所在的缓存条目的Flag表示相应缓存条目 是有效的,那么我们就称相应的内存操作产生了缓存命中(Cache Hit);否则,我们就称相应的内存操作 产生了缓存未命中(CacheMiss)。
具体来说,缓存未命中包括读未命中( Read Miss) 和写未命中( Write Mis),分别对应内存读和写操作。 当读未命中产生时,处理器所需读取的数据会从主内存中加载并被存人相应的缓存行之中。这个过程会导致 处理器停顿( Stall )而不能执行其他指令,这不利于发挥处理器的处理能力。因此,从性能的角度来看 我们应该尽可能地减少缓存未命中。
缓存一致性协议
多个线程并发访问同一个共享变量的时候,这些线程的执行处理器上的高速缓存各自都会保留一份该共享变量 的副本,这就带来一个新问题一一个处理器对其副本数据进行更新之后,其他处理器如何”察觉”到该更新并 做出适当反应,以确保这些处理器后续读取该共享变量时能够读取到这个更新。这就是缓存一致性问题,其 实质就是如何防止读脏数据和丢失更新的问题。为了解决这个问题,处理器之间需要一种通信机制 —— 缓存一致性协议( Cache Coherence Protocol )。
MESI ( Modified-Exclusive-Shared-Invalid )协议 是一种广为使用的缓存一致性协议,x86处理器 所使用的缓存一致性协议就是基于MESI协议的。MESI 协议对内存数据访问的控制类似于读写锁,它使得 针对同一地址的读内存操作是并发的,而针对同一地址的写内存操作是独占的,即针对同一内存地址进行的 写操作在任意-一个时刻只能够由一个处理器执行。在MESI协议中,一个处理器往内存中写数据时必须持有 该数据的所有权。
为了保障数据的一-致性,MESI将缓存条目的状态划分为Modified、Exclusive、Shared 和Invalid 这4种,并在此基础_上定义了–组消息(Message)用于协调各个处理器的读、写内存操作。 MESI协议中 一个缓存条目的Flag值有以下4种可能。
Invalid(无效的,记为I)。该状态表示相应缓存行中不包含任何内存地址对应的有效副本数据。该状态 是缓存条目的初始状态。Shared(共享的,记为S)。该状态表示相应缓存行包含相应内存地址所对应的副本数据。并且,其他 处理器上的高速缓存中也可能包含相同内存地址对应的副本数据。因此,一个缓存条目的状态如果为 Shared,并且其他处理器上也存在Tag值与该缓存条目的Tag值相同的缓存条目,那么这些缓存条目的 状态也为Shared。处于该状态的缓存条目,其缓存行中包含的数据与主内存中包含的数据一致。Exclusive(独占的,记为E)。该状态表示相应缓存行包含相应内存地址所对应的副本数据。并且, 该缓存行以独占的方式保留了相应内存地址的副本数据,即其他所有处理器上的高速缓存当前都不保留 该数据的有效副本。处于该状态的缓存条目,其缓存行中包含的数据与主内存中包含的数据一致。Modified(更改过的,记为M)。该状态表示相应缓存行包含对相应内存地址所做的更新结果数据。 由于MESI协议中的任意一个时刻只能够有一个处理器对同一内存地址对应的数据进行更新,因此在 多个处理器上的高速缓存中Tag值相同的缓存条目中,任意一个时刻只能够有一个缓存条目处于该状态。 处于该状态的缓存条目,其缓存行中包含的数据与主内存中包含的数据不一致。
MESI协议定义了- -组消息( Message)用于协调各个处理器的读、写内存操作,如表11-1所示。 比照HTTP协议,我们可以将MESI协议中的消息分为请求消息和响应消息。处理器在执行内存读、写操作 时在必要的情况下会往总线(Bus)中发送特定的请求消息,同时每个处理器还嗅探(Snoop,也称拦截) 总线中由其他处理器发出的请求消息并在一定条件下往总线中回复相应的响应消息。
MESI协议定义了- -组消息( Message )用于协调各个处理器的读、写内存操作,如表11-1所示。 比照HTTP协议,我们可以将MESI协议中的消息分为请求消息和响应消息。处理器在执行内存读、写操作时 在必要的情况下会往总线(Bus)中发送特定的请求消息,同时每个处理器还嗅探(Snoop,也称拦截)总线中 由其他处理器发出的请求消息并在一定条件下往总线中回复相应的响应消息。
表11-1 MESI 消息
| 消息名 | 消息类型 | 描述 |
|---|---|---|
| Read | 请求 | 通知其他处理器、主内存当前处理器准备读取某个数据。该消息包含 待读取数据的内存地址 |
| Read Response | 响应 | 该消息包含被请求读取的数据。该消息可能是主内存提供的,也可能 是嗅探Read消息的其他高速缓存提供的 |
| Invalidate | 请求 | 通知其他处理器将其高速缓存中指定内存地址对应的缓存条目状态置 为I,即通知这些处理器删除指定内存地址的副本数据 |
| Invalidate Acknowledge | 响应 | 接收到Invalidate 消息的处理器必须回复该消息,以表示删除了其 高速缓存上的相应副本数据 |
| Read Invalidate | 请求 | 该消息是由Read消息和Invalidate消息组合而成的复合消息。其作用 在于通知其他处理器当前处理器准备更新( Read-Modify-Write,读后 写更新) 一个数据,并请求其他处理器删除其高速缓存中相应的副本 数据。接收到该消息的处理器必须回复 Read Response消息和 Invalidate Acknowledge消息 |
| Writeback | 请求 |
写缓冲器和无效化队列
MESI协议解决了缓存一致性问题,但是其自身也存在一个性能弱点 —— 处理器执行写内存操作时, 必须等待其他所有处理器将其高速缓存中的相应副本数据删除并接收到这些处理器所回复的 Invalidate Acknowledge/Read Response消息之后才能将数据写人高速缓存。为了规避和 减少这种等待造成的写操作的延迟( Latency),硬件设计者引人了写缓冲器和无效化队列,如图11-6所示。
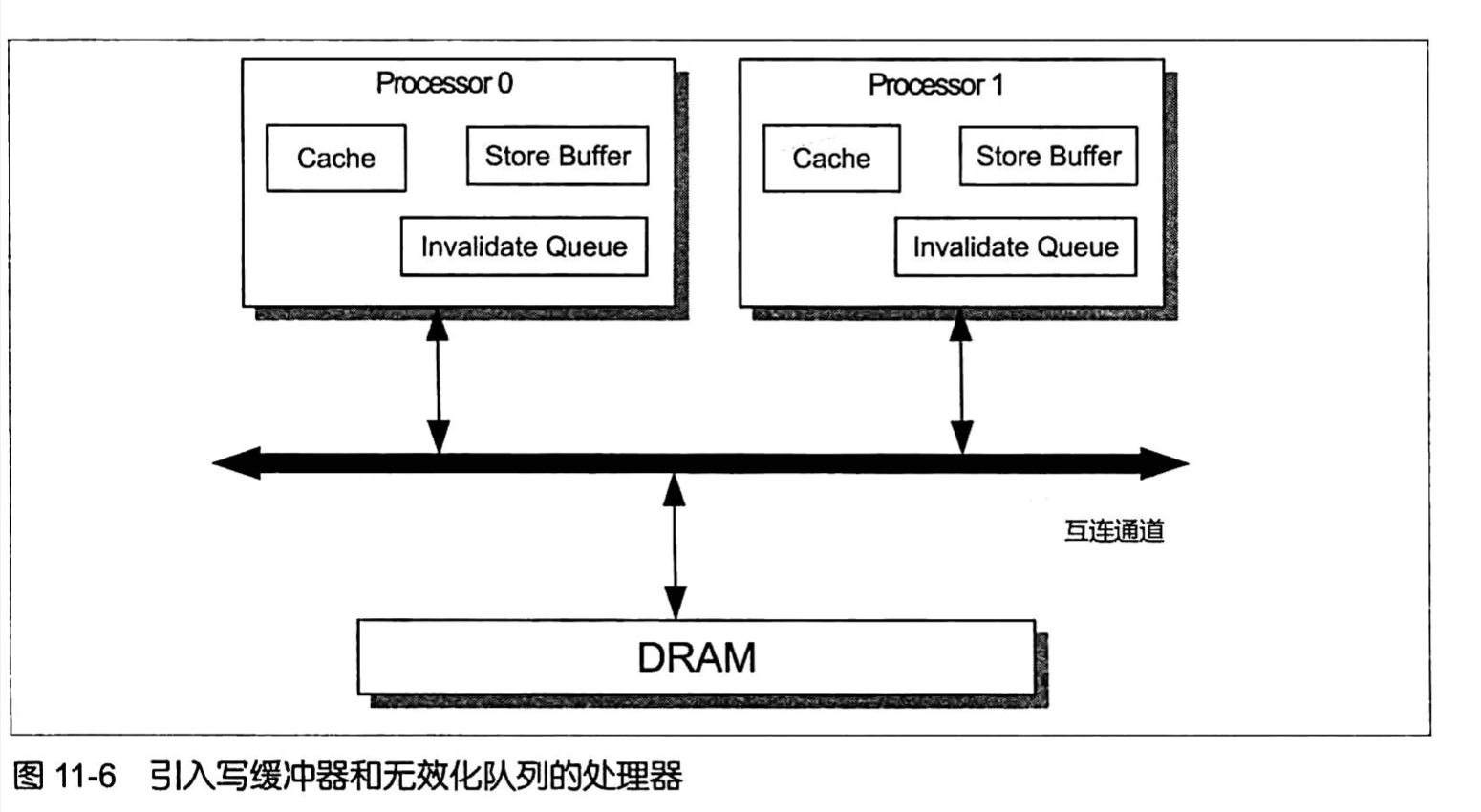
写缓冲器( Store Buffer,也被称为Write Buffer)是处理器内部的一个容量比高速缓存还小的 私有高速存储部件°,每个处理器都有其写缓冲器,写缓冲器内部可包含若干条目(Entry)。一个处理器 无法读取另外-一个处理器上的写缓冲器中的内容。
引入写缓冲器之后,处理器在执行写操作时会做这样的处理:如果相应的缓存条目状 态为E或者M,那么处理器可能会直接将数据写人相应的缓存行而无须发送任何消息; 如果相应的缓存条目状态为S,那么处理器会先将写操作的相关数据(包括数据和待操作 的内存地址)存人写缓冲器的条目之中,并发送Invalidate 消息;如果相应的缓存条目状. 态为I,我们就称相应的写操作遇到了写未命中(WriteMiss),那么此时处理器会先将写 操作相关数据存人写缓冲器的条目之中,并发送Read Invalidate消息。我们知道在其他所 有处理器的高速缓存都未保存指定地址的副本数据的情况下,Read消息回复者是主内存, 也就是说Read消息可能导致内存读操作。因此,写未命中的开销是比较大的。内存写操 作的执行处理器在将写操作的相关数据写人写缓冲器之后便认为该写操作已经完成,即该 处理器并不等待其他处理器返回InvalidateAcknowledge/ReadResponse消息而是继续执行 其他指令(比如执行读操作)。一个处理器接收到其他处理器所回复的针对同一个缓存条 目的所有InvalidateAcknowledge消息的时候,该处理器会将写缓冲器中针对相应地址的 写操作的结果写人相应的缓存行中,此时写操作对于其执行处理器之外的其他处理器来说 才算是完成的。
由此可见,写缓冲器的引人使得处理器在执行写操作的时候可以不等待Invalidate Acknowledge消息,从而减少了写操作的延时,这使得写操作的执行处理器在其他处理器 回复Invalidate Acknowledge/Read Response消息这段时间内能够执行其他指令,从而提高 了处理器的指令执行效率。
引入无效化队列( Invalidate Queue) 之后,处理器在接收到Invalidate消息之后并不 删除消息中指定地址对应的副本数据,而是将消息存人无效化队列之后就回复Invalidate Acknowledge消息,从而减少了写操作执行处理器所需的等待时间。有些处理器(比如x86) 可能没有使用无效化队列。
写缓冲器和无效化队列的引人又会带来一些新的问题 —— 内存重排序和可见性问题。
存储转发
引人写缓冲器之后,处理器在执行读操作的时候不能根据相应的内存地址直接读取相 应缓存行中的数据作为该操作的结果。这是因为一个处理器在更新一个变量之后紧接着又 读取该变量的值的时候,由于该处理器先前对该变量的更新结果可能仍然还停留在写缓冲 器之中,因此该变量相应的内存地址所对应的缓存行中存储的值是该变量的旧值。这种情 况下为了避免读操作所返回的结果是-一个旧值,处理器在执行读操作的时候会根据相应的 内存地址查询写缓冲器。如果写缓冲器存在相应的条目,那么该条目所代表的写操作的结 果数据就会直接作为该读操作的结果返回;否则,处理器才从高速缓存中读取数据。这种 处理器直接从写缓冲器中读取数据来实现内存读操作的技术被称为存储转发( Store Forwarding)。存储转发使得写操作的执行处理器能够在不影响该处理器执行读操作的情 况下将写操作的结果存入写缓冲器。
内存重排
写缓冲器和无效化队列都可能导致内存重排序。详见P388
可见性
写缓冲器是处理器内部的私有存储部件,一个处理器中的写缓冲器所存储的内容是无 法被其他处理器所读取的。因此,一个处理器上运行的线程更新了一个共享变量之后,其 他处理器上运行的线程再来读取该变量时这些线程可能仍然无法读取到前一个线程对该 变量所做的更新,因为这个更新可能还停留在前一个线程所在的处理器上的写缓冲器之 中。这种现象就是前面章节所说的可见性问题。因此,我们说写缓冲器是可见性问题的硬 件根源。因此,为了保证一个处理器对共享变量所做的更新可以被其他处理器 同步,编译器等底层系统需要借助一类被称为内存屏障的特殊指令。内存屏障中的存储屏 障(StoreBarrier)可以使执行该指令的处理器冲刷其写缓冲器。
然而,冲刷写缓冲器只是解决了可见性问题的一半。因为可见性问题的另一半是无效 化队列导致的。无效化队列的引入本身也会导致新的问题一处理器在执行内存读取操作 前如果没有根据无效化队列中的内容将该处理器上的高速缓存中的相关副本数据删除,那 么就可能导致该处理器读到的数据是过时的旧数据,从而使得其他处理器所做的更新丢 失。因此,为了使一个处理器上运行的线程能够读取到另外一个处理器上运行的线程对共 享变量所做的更新,该处理器必须先根据无效化队列中存储的Invalidate消息删除其高速 缓存中的相应副本数据,从而使其他处理器上运行的线程对共享变量所做的更新在缓存– 致性协议的作用下能够被同步到该处理器的高速缓存之中。内存屏障中的加载屏障(Load Barrier)正是用来解决这个问题的。加载屏障会根据无效化队列内容所指定的内存地址, 将相应处理器上的高速缓存中相应的缓存条目的状态都标记为I,从而使该处理器后续执 行针对相应地址(无效化队列内容中指定的地址)的读内存操作时必须发送Read消息, 以将其他处理器对相关共享变量所做的更新同步到该处理器的高速缓存中。
基本内存屏障
处理器支持哪种内存重排序(LoadLoad重排序、LoadStore重排序、StoreStore重排 序和StoreLoad重排序),就会提供能够禁止相应重排序的指令,这些指令就被称为基本内 存屏障一LoadLoad 屏障、LoadStore 屏障、StoreStore 屏障和StoreLoad屏障。基本内存 屏障可以统一用XY来表示,其中的X和Y可以代表Load或者Store。基本内存屏障是 对一类指令的称呼,这类指令的作用是禁止该指令左侧的任何X操作与该指令右侧的任 何Y操作之间进行重排序,从而确保该指令左侧的所有X操作先于该指令右侧的Y操作 被提交,即内存操作作用到主内存(或者高速缓存)上,如表11-6 所示。比如,StoreLoad 屏障(即X代表Store,Y代表Load)能够禁止其左侧的任何写操作与其右侧的任何读操 作之间进行重排序,因此StoreLoad屏障就保障了该指令之前的写操作的结果在该指令之 后的任何读操作的数据被加载之前对其他处理器来说可同步,即这些写操作的结果会在该 屏障之后的读操作的数据被加载前被写人高速缓存(或者主内存)。
表11-6
| 屏障名称 | 示例 | 基本作用 |
|---|---|---|
| StoreLoad | Store1;Store2;Store3; StoreLoad; Load1;Load2;Load3 | 禁止StoreLoad重排序,即确保该屏障之前的任何一个 写操作(比如Store2 )的结果都会在该屏障之后的任何 一个读操作(比如Load1)的数据被加载之前对其他处理 器来说是可同步的 |
| StoreStore | Store1;Store2;Store3; StoreLoad; Store4;Store5;Store6 | 禁止StoreStore重排序,即确保该屏障之前的任何一个 写操作(比如Store1)的结果都会在该屏障之后的任何 一个写操作(比如Store4)之前对其他处理器来说是可 同步的 |
| LoadLoad | Load1;Load2;Load3; LoadLoad; Load4;Load5;Load6 | 禁止LoadLoad重排序,即确保该屏障之前的任何一个 读操作(比如Load1 )的数据都会在该屏障之后的任何 一个读操作(比如Load4)之前被加载 |
| LoadStore | Load1;Load2;Load3; LoadStore; Store1; Store2; Store3 | 禁止LoadStore重排序,即确保该屏障之前的任何一个 读操作(比如Loadl )的数据都会在该屏障之后的任何 一个写操作(比如Storel )的结果被冲刷(写人)到高速 缓存(或者主内存)之前被加载 |
基本内存屏障的作用只是保障其左侧的X操作(比如读,即X代表Load)先于其右 侧的Y操作(比如写,即Y代表Store)被提交,它并不全面禁止重排序。XY屏障两侧 的内存操作仍然可以在不越过内存屏障本身的情况下在各自的范围内进行重排序,并且 XY屏障左侧的非X操作与屏障右侧的非Y操作之间仍然可以进行重排序(即越过内存屏 障本身)。例如,在图11-7所示的指令序列中Load2、Load3和Store1、Store2之间无法进 行重排序,而Store1、Load1和Store2之间可以重排序,Store3、Load2和Load3之间可 以重排序,Load1和Store3之间也可以进行重排序。
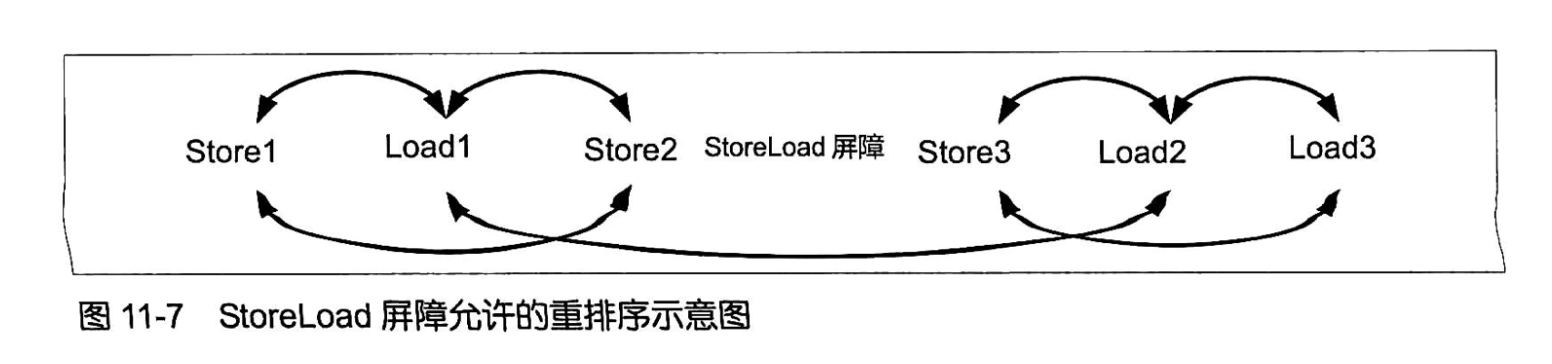
编译器(JIT编译器)、运行时(Java虚拟机)和处理器都会尊重内存屏障,从而保障 其作用得以落实。例如,在图11-7所示的指令序列中,假如编译器不尊重内存屏障而在 其动态编译(JIT 编译)的时候将Storel 重排序( 指令重排序)到Load2之后,那么显然 StoreLoad屏障被架空了:它并无法保障Storel先于Load2被提交。因此,内存屏障需要 得到编译器等多方的尊重,其作用才能落实。
参考资料
文档信息
- 本文作者:Bob.Zhu
- 本文链接:https://adolphor.github.io/2021/08/23/04-concurrent-memory-model/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)