
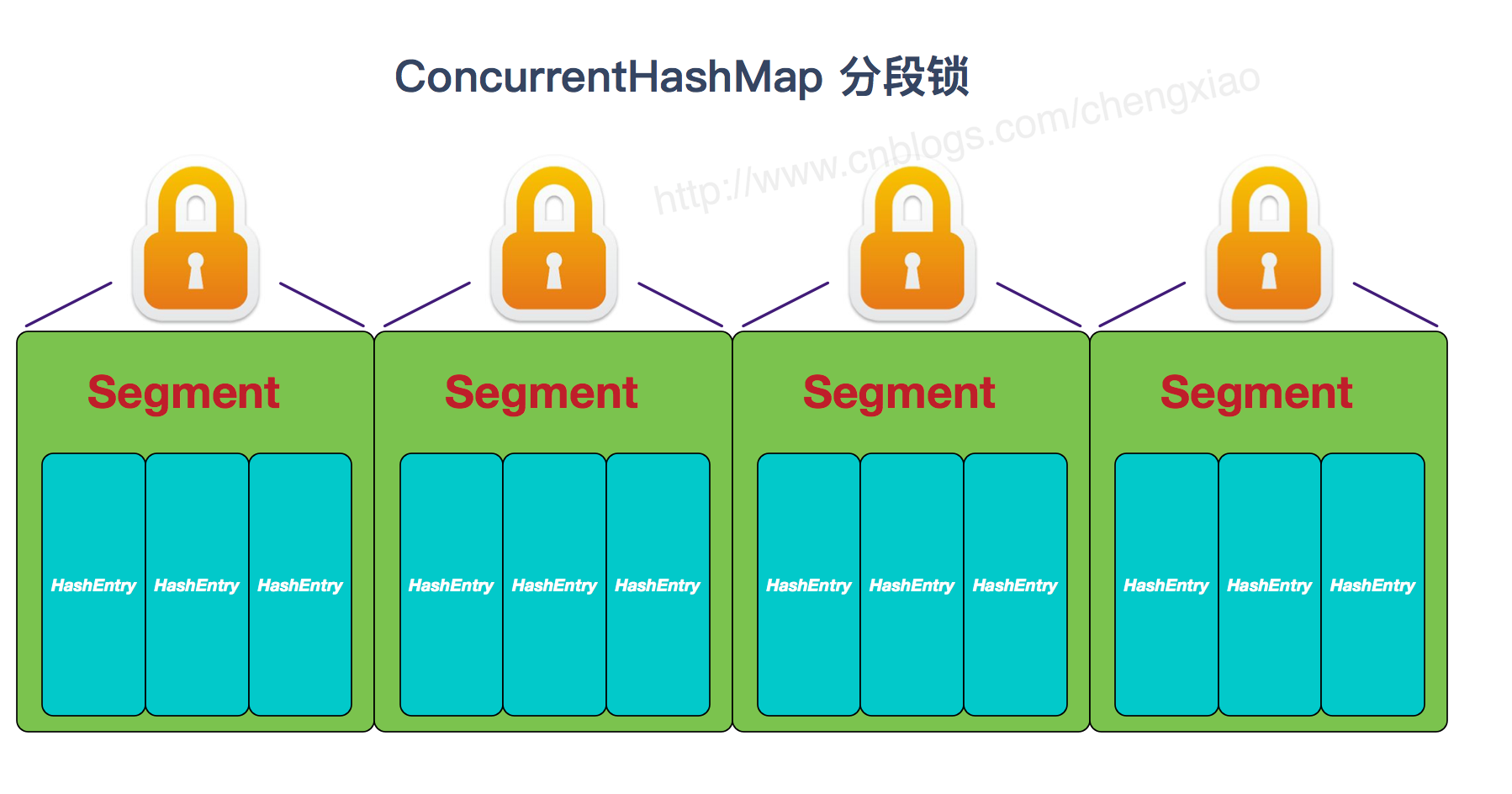
Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作, 每一个 Segment 都是一个类似 HashMap 数组的结构, 它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
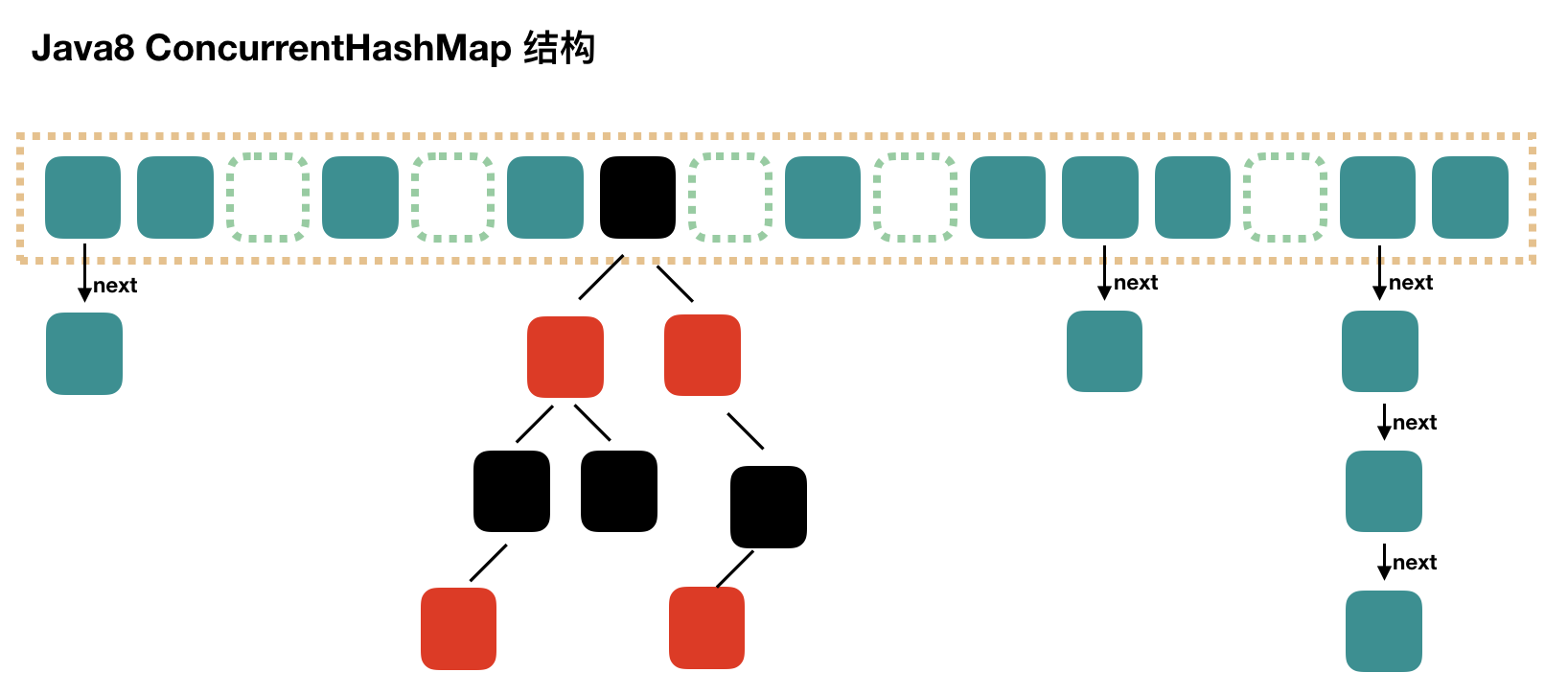
Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 S egment 数组 + HashEntry 数组 + 链表 进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
JDK1.7
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。 ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。 Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
JDK1.8
ConcurrentHashMap 1.8 取消了 Segment 分段锁,采用 CAS 和 synchronized 来保证并发安全。 数据结构跟 HashMap1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表 (寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。
synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。
Hashtable 比较
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同:
- 底层数据结构
- ConcurrentHashMap
- JDK1.7:分段的数组+链表
- JDK1.8:数组+链表/红黑二叉树(和HashMap1.8的数据结构一样)
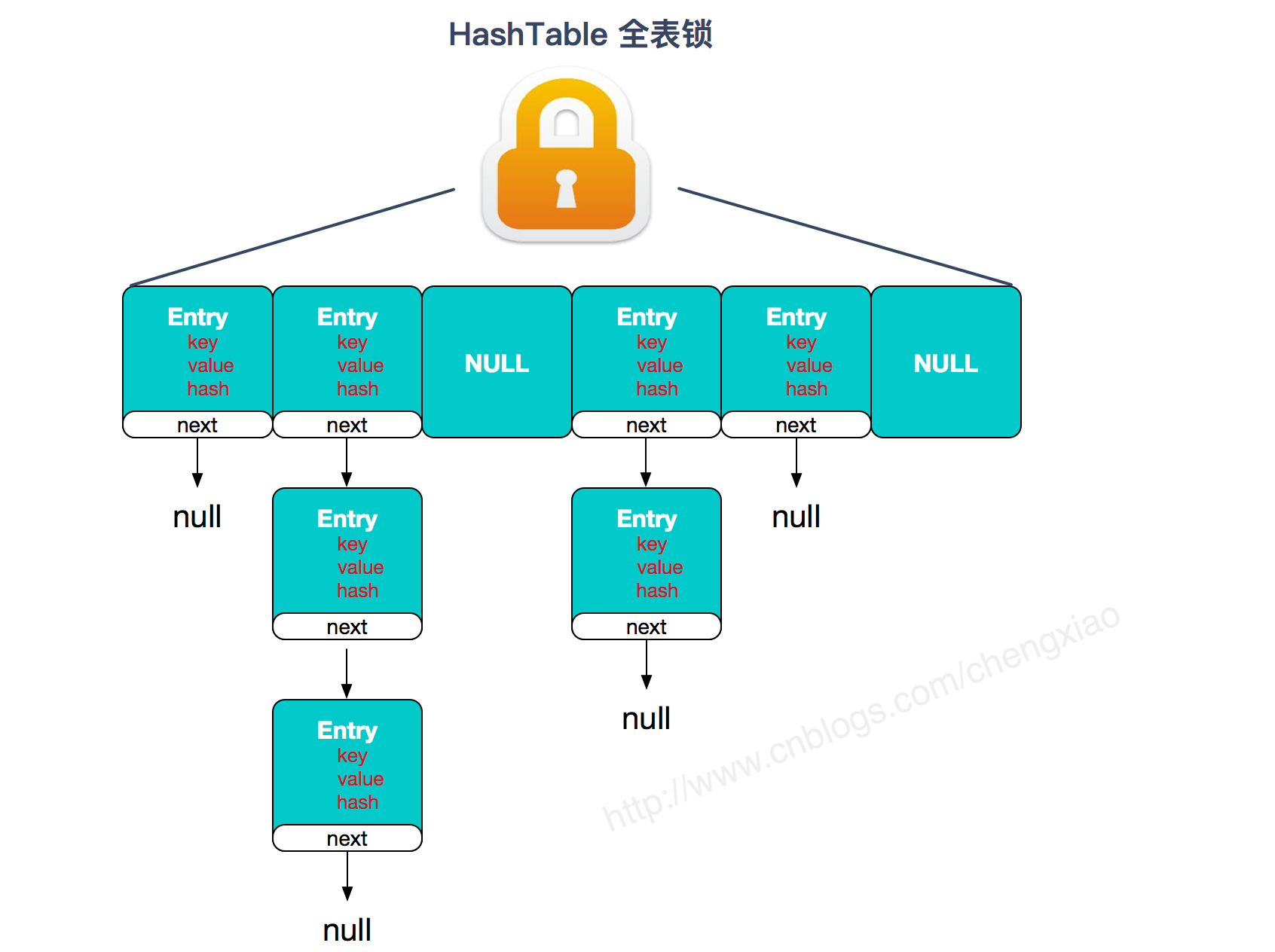
- Hashtable:数组+链表
- ConcurrentHashMap
- 实现线程安全的方式(重要)
- ConcurrentHashMap
- JDK1.7:(分段锁) 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争
- JDK1.8:摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作;虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本
- Hashtable:使用 synchronized 来保证线程安全,效率非常低下。
- ConcurrentHashMap
参考资料
文档信息
- 本文作者:Bob.Zhu
- 本文链接:https://adolphor.github.io/2021/09/27/02-jdk-ConcurrentHashMap/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)