
线程是一个重资源,JVM 中的线程与操作系统的线程是一对一的关系,所以在 JVM 中每创建一个线程 就需要调用操作系统提供的 API 创建线程,赋予资源,并且销毁线程同样也需要系统调用。 而系统调用就意味着上下文切换等开销,并且线程也是需要占用内存的,而内存也是珍贵的资源。 因此线程的创建和销毁是一个重操作,并且线程本身也占用资源。
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。 线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时 创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式, 这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
小结一下:
- Java中线程与操作系统线程是一比一的关系。
- 线程的创建和销毁是一个“较重”的操作。
- 多线程的主要是为了提高 CPU 的利用率。
- 线程的切换有开销,线程数的多少需要结合 CPU核心数与 I/O 等待占比。
线程池
池化技术
池化,顾名思义,是为了最大化收益并最小化风险,而将资源统一在一起管理的一种思想。
Pooling is the grouping together of resources (assets, equipment, personnel, effort, etc.)
for the purposes of maximizing advantage or minimizing risk to the users. The term is used
in finance, computing and equipment management. ——wikipedia
“池化”思想不仅仅能应用在计算机领域,在金融、设备、人员管理、工作管理等领域也有相关的应用。 在计算机领域中的表现为:统一管理IT资源,包括服务器、存储、和网络资源等等。通过共享资源, 使用户在低投入中获益。除去线程池,还有其他比较典型的几种使用策略包括:
- 内存池(Memory Pooling):预先申请内存,提升申请内存速度,减少内存碎片。
- 连接池(Connection Pooling):预先申请数据库连接,提升申请连接的速度,降低系统的开销。
- 实例池(Object Pooling):循环使用对象,减少资源在初始化和释放时的昂贵损耗。
线程池好处
降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。提高响应速度:任务到达时,无需等待线程创建即可立即执行。提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
线程池总体设计
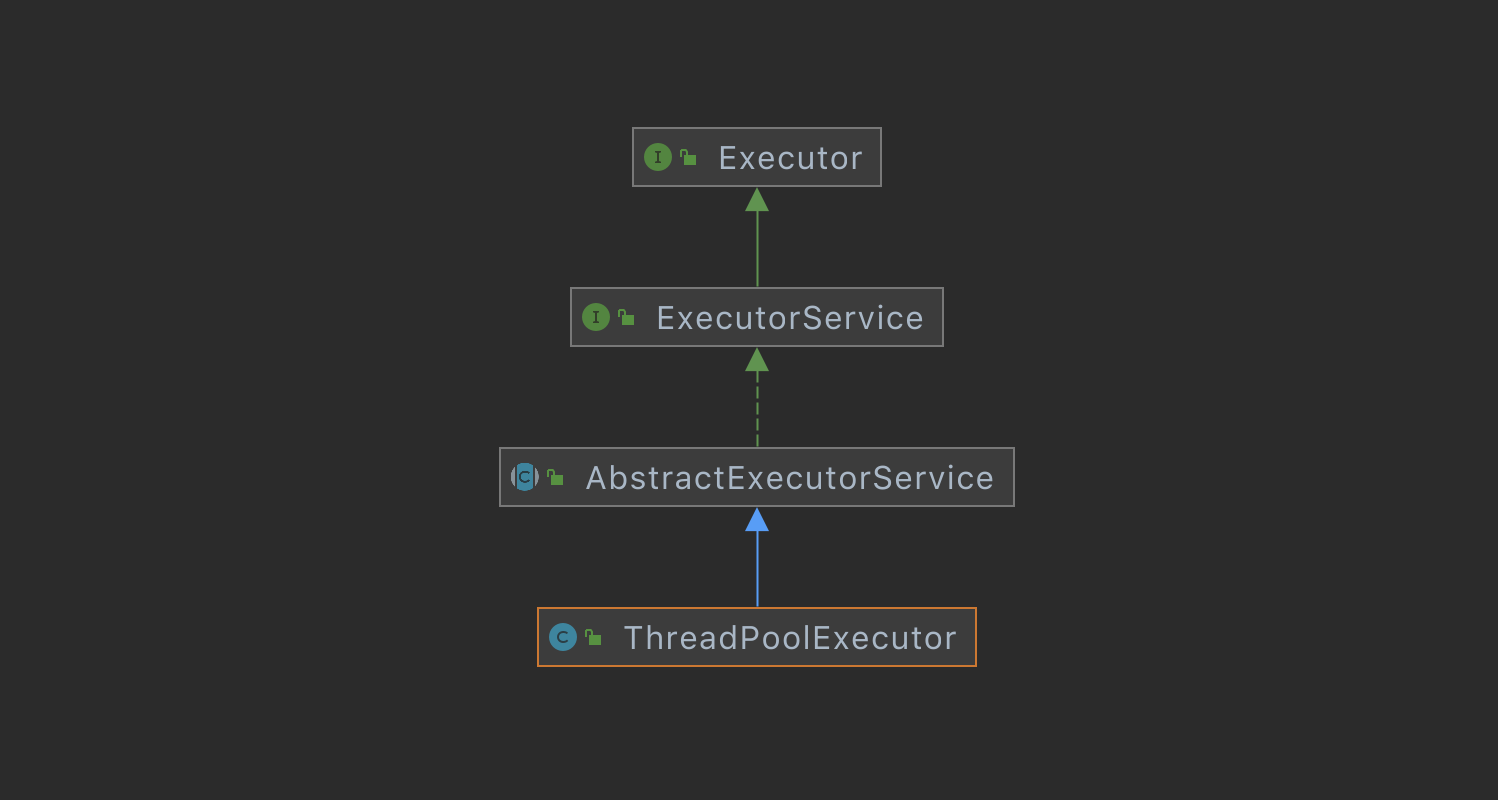
ThreadPoolExecutor实现的顶层接口是Executor,顶层接口Executor提供了一种思想:将任务提交和任务执行进行解耦。 用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供Runnable对象,将任务的运行逻辑提交到执行器(Executor)中, 由Executor框架完成线程的调配和任务的执行部分。ExecutorService接口增加了一些能力:(1)扩充执行任务的能力, 补充可以为一个或一批异步任务生成Future的方法;(2)提供了管控线程池的方法,比如停止线程池的运行。 AbstractExecutorService则是上层的抽象类,将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。 最下层的实现类ThreadPoolExecutor实现最复杂的运行部分,ThreadPoolExecutor将会一方面维护自身的生命周期, 另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
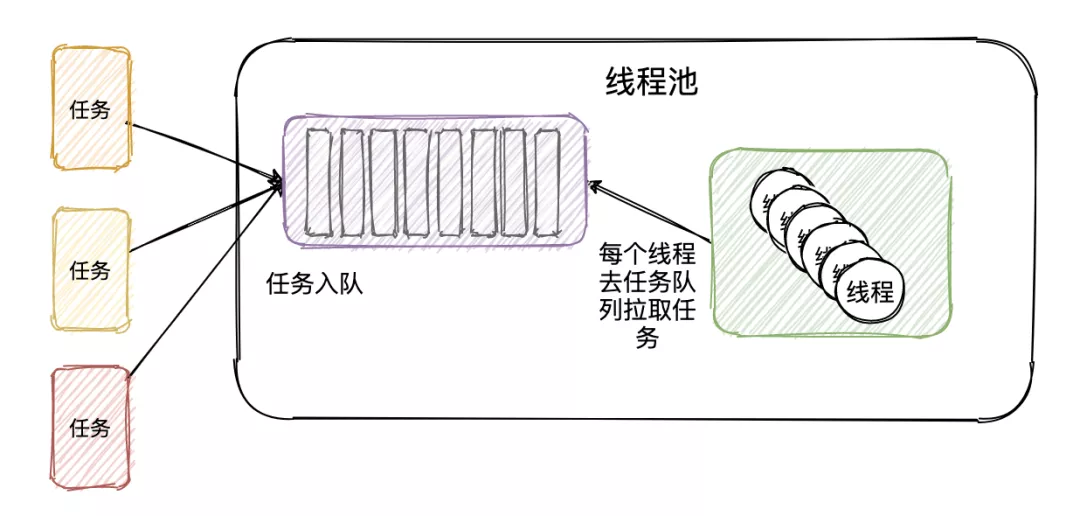
线程池在内部实际上构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。 线程池的运行主要分成两部分:任务管理、线程管理。任务管理部分充当生产者的角色,当任务提交后, 线程池会判断该任务后续的流转:(1)直接申请线程执行该任务;(2)缓冲到队列中等待线程执行; (3)拒绝该任务。线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配, 当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
创建方式
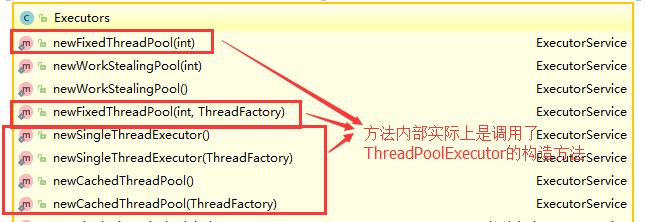
通过 ThreadPoolExecutor 构造方法实现

通过 Executor 框架的工具类 Executors 来实现
我们可以创建三种类型的 ThreadPoolExecutor:
- SingleThreadExecutor
- FixedThreadPool
- CachedThreadPool
SingleThreadExecutor
方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中, 待线程空闲,按先入先出的顺序执行队列中的任务。
FixedThreadPool
该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时, 线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时, 便处理在任务队列中的任务。
CachedThreadPool
该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用, 则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。 所有线程在当前任务执行完毕后,将返回线程池进行复用。
ThreadPoolExecutor 类分析
ThreadPoolExecutor 类中提供的四个构造方法。我们来看最长的那个,其余三个都是在这个构造方法的基础上产生 (其他几个构造方法说白点都是给定某些默认参数的构造方法比如默认制定拒绝策略是什么),这里就不贴代码讲了,比较简单。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ? null : AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
ThreadPoolExecutor 3 个最重要的参数:
corePoolSize:核心线程数线程数定义了最小可以同时运行的线程数量。maximumPoolSize:当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。workQueue:当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
ThreadPoolExecutor 其他常见参数:
keepAliveTime:当线程池中的线程数量大于 corePoolSize 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 keepAliveTime才会被回收销毁;unit:keepAliveTime 参数的时间单位。threadFactory:executor 创建新线程的时候会用到。handler:饱和策略。关于饱和策略下面单独介绍一下。
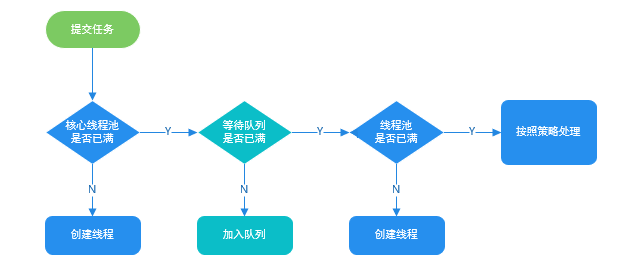
corePoolSize 核心线程数量
判断运行线程数是否小于 corePoolSize,如果小于,则直接创建新的线程执行。
workQueue 阻塞队列
如果大于 corePoolSize,判断 workQueue 阻塞队列是否已满, 如果还没满,则把任务放到阻塞队列中。
maximumPoolSize 最大线程数量
如果 workQueue 阻塞队列已经满了,判断当前线程数是否已经大于 maximumPoolSize 最大线程数量, 如果没大于,则创建新的线程执行。
keepAliveTime 线程空余时间
当前运行的线程数大于 corePoolSize 核心线程数量的时候,只要空闲时间到了, 就会进行线程的回收。
看到这里你可能会觉得核心线程在线程池里面会有特殊标记? 并没有,不论是核心还是非核心线程,在线程池里面都是一视同仁,当淘汰的时候不会管是哪些线程, 反正留下核心线程数个线程即可,下文会作详解。
handler 任务决绝策略
如果大于 maximumPoolSize 最大线程数量,则执行任务拒绝策略。
ThreadPoolTaskExecutor 定义一些策略:
ThreadPoolExecutor.AbortPolicy
抛出 RejectedExecutionException 来拒绝新任务的处理。这也是缺省时的默认策略。
ThreadPoolExecutor.CallerRunsPolicy
调用执行自己的线程运行任务,也就是直接在调用execute方法的线程中运行(run)被拒绝的任务, 如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。 如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
ThreadPoolExecutor.DiscardPolicy
不处理新任务,直接丢弃掉。
ThreadPoolExecutor.DiscardOldestPolicy
此策略将丢弃最早的未处理的任务请求。
unit 线程空余时间的单位
threadFactory
线程池的状态和生命周期
线程池的状态分类
- running:当线程池创建后,初始为 running 状态,能接受新任务,并处理阻塞队列中的任务
- shutdown:调用 shutdown 方法后,处在shutdown 状态,此时不再接受新的任务,但是可以处理阻塞队列中的任务,直到已有的任务执行完毕
- stop:调用 shutdownnow 方法后,进入 stop 状态,不再接受新的任务,并且会尝试终止正在执行的任务。
- tidying:并且所有工作线程已经销毁,任务缓存队列已清空,线程池被设为 tidying 状态,等待执行 terminated() 钩子方法
- terminated状态:terminated() 方法执行完毕,线程池处于关闭状态
线程池的状态如何变化
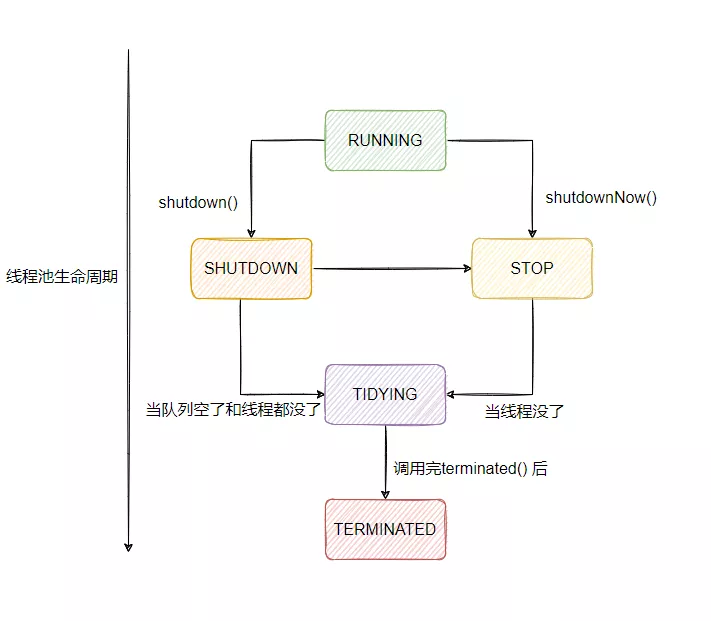
- RUNNING -> SHUTDOWN: On invocation of shutdown(), perhaps implicitly in finalize()
- (RUNNING or SHUTDOWN) -> STOP: On invocation of shutdownNow()
- SHUTDOWN -> TIDYING: When both queue and pool are empty
- STOP -> TIDYING: When pool is empty
- TIDYING -> TERMINATED: When the terminated() hook method has completed
核心线程的扩容时机
线程池本意只是让核心数量的线程工作着,不论是 core 的取名,还是 keepalive 的设定, 所以你可以直接把 core 的数量设为你想要线程池工作的线程数,而任务队列起到一个缓冲的作用。 最大线程数这个参数更像是无奈之举,在最坏的情况下做最后的努力,去新建线程去帮助消化任务。
通过 ThreadPoolExecutor 类中构造器参数的分析,我们知道,当任务超过核心线程数量的时候, 其他的任务会放入阻塞队列,当阻塞队列中任务满了以后,才会扩充线程数量。这么做的话,当任务多的时候, 就会造成虽然服务器有能力处理,任务却还在等待中的情况。那么是否可以先扩容,扩容到最大线程数量 如果任务还处理不完,再放入阻塞队列中呢?答案是可以的。
Tomcat 就是使用的这种策略,来看下具体是怎么实现的。
首先,添加依赖,方便查看源码:
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-core</artifactId>
<version>9.0.48</version>
</dependency>
在 org.apache.tomcat.util.threads 包下,找到 ThreadPoolExecutor.java, tomcat 中的 ThreadPoolExecutor 继承自 java.util.concurrent.ThreadPoolExecutor, 并且任务队列使用的是 TaskQueue(继承自 LinkedBlockingQueue<Runnable>):
public class ThreadPoolExecutor extends java.util.concurrent.ThreadPoolExecutor {
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static int ctlOf(int rs, int wc) {
return rs | wc;
}
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
prestartAllCoreThreads();
}
public void execute(Runnable command, long timeout, TimeUnit unit) {
// 统计提交的任务数
submittedCount.incrementAndGet();
try {
// 调用原生的线程池提交任务
super.execute(command);
}
// 捕获线程池拒绝异常
catch (RejectedExecutionException rx) {
if (super.getQueue() instanceof TaskQueue) {
final TaskQueue queue = (TaskQueue) super.getQueue();
try {
// 再次尝试把人无语塞到任务队列
if (!queue.force(command, timeout, unit)) {
// 如果塞不进去,把之前统计的任务数-1
submittedCount.decrementAndGet();
throw new RejectedExecutionException(sm.getString("threadPoolExecutor.queueFull"));
}
} catch (InterruptedException x) {
// 被打断了,统计的任务-1
submittedCount.decrementAndGet();
throw new RejectedExecutionException(x);
}
} else {
// 如果不是定制的任务队列,任务数-1
submittedCount.decrementAndGet();
throw rx;
}
}
}
}
Tomcat 维护了一个 submittedCount 变量,这个变量的含义是统计已经提交的但是还未完成的任务数量 (记住这个变量,很关键),所以只要提交一个任务,这个数就加一,并且捕获了拒绝异常, 再次尝试将任务入队,这个操作其实是为了尽可能的挽救回一些任务,因为这么点时间差可能已经执行完很多任务, 队列腾出了空位,这样就不需要丢弃任务。
然后我们再来看下代码里出现的 TaskQueue,这个就是上面提到的定制关键点了。
public class TaskQueue extends LinkedBlockingQueue<Runnable> {
private transient volatile ThreadPoolExecutor parent = null;
public boolean offer(Runnable o) {
//we can't do any checks
if (parent == null) {
// 没传入线程池实例,该怎么样就怎样
return super.offer(o);
}
//we are maxed out on threads, simply queue the object
if (parent.getPoolSize() == parent.getMaximumPoolSize()) {
// 已经达到最大线程池数量,该怎样就怎样
return super.offer(o);
}
//we have idle threads, just add it to the queue
if (parent.getSubmittedCount()<=(parent.getPoolSize())) {
// 获取当前线程池中已提交未完成的任务数量,如果小于当前线程数,说明有线程空闲,直接入队即可
return super.offer(o);
}
//if we have less threads than maximum force creation of a new thread
if (parent.getPoolSize()<parent.getMaximumPoolSize()) {
// 走到这里说明没有线程空闲,如果当前线程数小于最大线程,那么直接返回false就可以在后续创建新线程来处理任务了
return false;
}
//if we reached here, we need to add it to the queue
return super.offer(o);
}
}
可以看到这个任务队列继承了 LinkedBlockingQueue,并且有个 ThreadPoolExecutor 类型的成员变量 parent ,再来看下 offer 方法的实现,就是修改原来线程池任务提交与线程创建逻辑的核心。
线程数量的指定
线程池指定线程数,需要考量自己的业务是CPU密集型还是IO密集型,假设服务器CPU数量是N, 那么经验的做法是:CPU密集型可以给到N+1,IO密集型可以给到2N。具体开多少线程,还需要 压测才能准确的确定下来。
线程数量不是设置的越多越好,多线程是为了充分利用CPU资源,如果设置的线程数量过多,则 会有大量的上下文切换,会带来系统的开销,反而得不偿失。
ctl
线程池里的 ctl 是干嘛的?
其实看下注释就很清楚了,ctl 是一个涵盖了两个概念的原子整数类,它将工作线程数和线程池状态 结合在一起维护,低 29 位存放 workerCount,高 3 位存放 runState。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
其实并发包中有很多实现都是一个字段存多个值的,比如读写锁的高 16 位存放读锁,低 16 位存放写锁, 这种一个字段存放多个值可以更容易的维护多个值之间的一致性,也算是极简主义。
其他QA
原生线程池的核心线程一定伴随着任务慢慢创建的吗?
并不是,线程池提供了两个方法:
- prestartCoreThread:启动一个核心线程
- prestartAllCoreThreads :启动所有核心线程
不要小看这个预创建方法,预热很重要,不然刚重启的一些服务有时是顶不住瞬时请求的,就立马崩了, 所以有预热线程、缓存等等操作。
如何动态修改核心线程数和最大线程数
其实之所以会有这样的需求是因为线程数是真的不好配置。很难通过一个公式一劳永逸, 线程数的设定是一个迭代的过程,需要压测适时调整,以上的公式做个初始值开始调试是 ok 的。
线程池其实已经给予方法暴露出内部的一些状态,例如正在执行的线程数、已完成的任务数、队列中的任务数等等。
也可以继承线程池增加一些方法来修改,看具体的业务场景了。同样搞个页面,然后给予负责人员配置修改即可。
当然你可以想要更多的数据监控都简单的,像 Tomcat 那种继承线程池之后自己加呗,动态调整的第一步 监控就这样搞定了!定时拉取这些数据,然后搞个看板,再结合邮件、短信、钉钉等报警方式, 我们可以很容易的监控线程池的状态!
示例
public class ThreadPoolExecutorDemo {
private static final int CORE_POOL_SIZE = 5;
private static final int MAX_POOL_SIZE = 10;
private static final int QUEUE_CAPACITY = 100;
private static final Long KEEP_ALIVE_TIME = 1L;
public static void main(String[] args) {
//使用阿里巴巴推荐的创建线程池的方式
//通过ThreadPoolExecutor构造函数自定义参数创建
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAX_POOL_SIZE,
KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 10; i++) {
//创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
Runnable worker = new MyRunnable(String.valueOf(i));
//执行Runnable
executor.execute(worker);
}
//终止线程池
executor.shutdown();
while (!executor.isTerminated()) {
}
System.out.println("Finished all threads");
}
}
public class MyRunnable implements Runnable {
private String command;
public MyRunnable(String s) {
this.command = s;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
processCommand();
System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
}
private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return this.command;
}
}
参考资料
文档信息
- 本文作者:Bob.Zhu
- 本文链接:https://adolphor.github.io/2021/09/27/04-java-concurrent-ThreadPool/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)