
未经验证的可观察性和随时待命的团队总会不可避免地遇到反应中断,而要想减少中断是很痛苦的,因为这就像蒙住双眼在大海捞针。我之所以知道这些,是因为我曾稳定了经历过混乱的团队。
- 未检测到的降级导致用户感到痛苦。
- 无休止的、海啸般的嘈杂警报。
- 24 小时待命压力,难以承受,不可持续。
影响团队永久反应的四个原因
脱节(Disconnect)
组织对用户体验的感知与实际用户体验之间存在鸿沟。感知与现实脱节的一些典型症状包括:
- 尽管监控系统报告的状态为“健康”,但用户的投诉仍源源不断。
- 缺乏主动的故障检测,只有在用户投诉时才能检测到中断。
- 工程师试图解释页面如何影响用户。
- 一位工程师意外地发现了残缺的功能。
不信任(Distrust)
一个大的危险信号是对触发警报缺乏信心。监控系统发出的错误警报越多,工程师们就越不信任这个系统。不幸的是,这种低信噪比的状态加速了失修周期;工程师们厌倦了不断喊“狼来了”的监视器,直到不再关注这个问题。在这个阶段,你就应该拿着爆米花,等待不可避免的大规模中断。
组织混乱(Disorganization)
没有特定的案例,给到的“建议方法”取决于你与谁合作。这种缺乏组织性和清晰指导的表现为监控框架激增、缺乏实战检验的工具以及临时中断补救措施。工程师们总是采取碰运气的解决方案,例如重启电脑,并希望“问题”消失)。
失修(Disrepair)
工具、系统和警报已经失修。产生问题的原因各不相同,有的是服务处于维护模式,有的是由于损耗而缺乏专门知识,还有的则是半死不活的项目。
监控策略是怎样令用户失望的
监控的目标就是要保证用户的良好体验,主动把问题扼杀在摇篮里,或者能够迅速缓解没有捕捉到的问题。事实上,大部分方案都未能达到这个目标,原因并非是存在工具方面的差距,而是因为工具使用不当,这意味着并没有理解核心问题出在哪里。
这一问题的显著特征之一就是,疲于救火的团队数量与可观察性工具的数量相当。事实上,如果仅仅是工具的问题,那么使用 Prometheus/Nagios/geneva/kusto/ 等等,就能解决这个问题。
用户需要的是什么?举个例子,在使用文字处理软件时,我需要的是把东西写好并完成工作,我不关心内存使用情况或处理器速度。因此,偶尔的冻结或者崩溃是可以忍受的——我抱怨着重启程序,然后恢复工作。然而,如果我丢失了我的工作文件,或者如果重启或刷新或后仍然存在问题,我就会感到沮丧。
用户只有在造成不可逆转的损害时才会关心这个故障。偶尔出现的崩溃、YouTube 故障或 PC 冻结都是可以忍受的,因为它是暂时的。
可观察性策略必须回答的关键问题就是:你的用户是否满意?要回答这个问题,就需要了解你的用户,知道什么能让他们满意。对这个问题的回答将渗透到可观测性栈中,并且会对连贯的操作实践产生影响。
让用户满意的要素
- 产品团队,性能、可靠性、持久性。有关更多信息,请参见 No Surprises 文章。
- Usability:It should work
- Performance:It should be fast
- Reliability:It should not lose data
- Integrity:It should be available when needed
- Security:It should not leak data
- 平台团队,不要止步于使用您服务的直接团队,还要尝试了解这些合作伙伴团队的用户。
软件质量的马斯洛层次
优先考虑质量问题的层次结构: 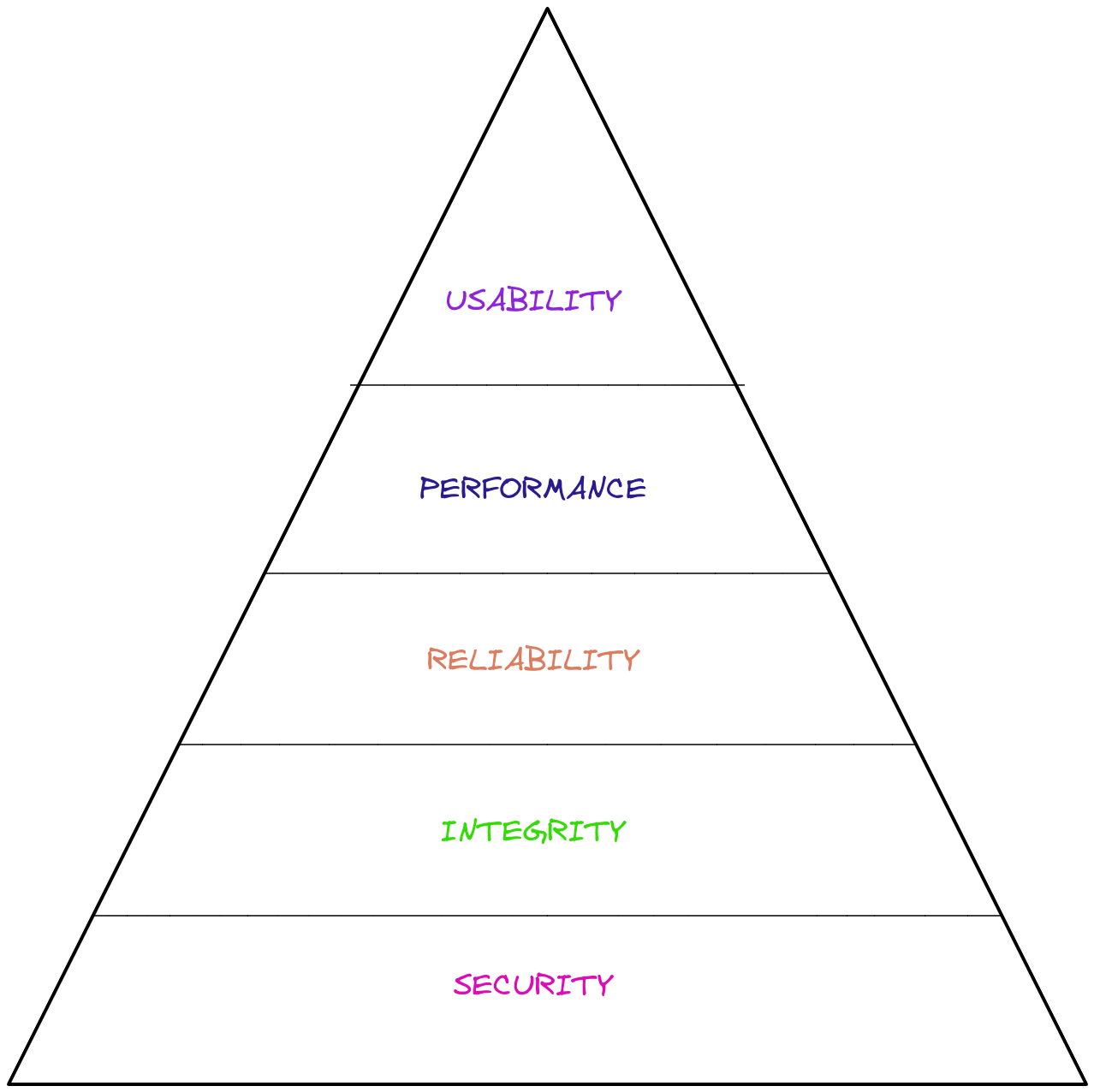
一些用户不满意的代理指标的要素
- 可靠性:由于内部系统错误而导致的故障和不可靠的结果(例如,错误对话框)。
- 延迟性:操作花费的时间比预期的要长(例如,一个请求需要 10 秒钟而不是 2 秒钟)。
- 可用性:不应向用户显示的内部错误(例如,隐晦的通用消息或对用户不友好的调试日志)。
- 持久性:任务关键型系统中的数据丢失(例如,无法保存)。
- 可用性:当需要处理请求时,系统不可用(例如,无法访问服务器)。
为什么需要一个好的可观察性指标?
以用户为中心的可观察性指标有两个目标:
指导完成目标
它们用户为改善服务提供了一个目标灯塔——帮助确定优先次序、跟踪修复工作,并将重点放在杠杆率最高的干预措施上。它们也可以被整合到组织实践中(如服务审查、事后检查等),以确保细微的偏差不会被忽视(如几周内健康趋势下降了 0.05%)。
主动警报
它们高度准确,可以提供回归的早期警报。健康指标的任何突然和持续下降都与真正的用户影响直接相关。在这些指标上设置警报将弥补生产上的可观察性差距。
CAR 框架
下面,让我们讨论一个经过实战检验和验证的成熟策略。
CAR 框架的三个实体:用户、应用程序和资源
CAR 代表“用户”(Customer)、“应用程序”(Application)和“资源”(Resource),它通过建立三个实体(用户、应用程序和底层资源)之间的交互,提供监视脱节的解决方案:
- 用户:想要完成一些事情(如撰写文档、看 YouTube)。满意度取决于应用程序是否按预期工作。
- 应用程序:用于解决问题。应用程序可能出现崩溃或错误,完备的应用程序如果资源匮乏也会出现问题。
- 资源:为应用程序提供合适的主机,例如 CPU、内存和 I/O,这些是应用程序顺利运行所必需的。
它像测试金字塔一样确保了重叠的监视覆盖,从而确保了测试覆盖。

CAR 金字塔展示了用户、应用程序和资源之间的关系:资源(如虚拟机、缓存)构成了构建应用程序的基础;反过来,应用程序是为了满足用户的需求而构建的。 大多数策略都假定健康的应用程序和资源能够保证优秀的用户体验,但这种假设并不总是正确。
使用 CAR 的结果
识别盲点
检测以前不会被注意到的中断,揭露系统中长期隐藏和存在的缺陷,从而进行适当的架构修复。
减少工作量
事故的数量级下降(主要是由于消除了噪音监视器)。
信任
警报意味着真正的用户问题,工程师有动力去找出根本原因。这比表面处理嘈杂的监视器要好得多。
主动执行
减少事件量和暴露架构缺陷的工作量有助于团队从反应性救火转向主动、集中解决问题。
参考资料
文档信息
- 本文作者:Bob.Zhu
- 本文链接:https://adolphor.github.io/2023/03/11/01-why-most-monitoring-strategies-fail/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)