
ShardingJdbc 分库分表,原文来源:手把手教你实现分库分表
分库分表带来的复杂性
跨库关联查询
在单库未拆分表之前,我们可以很方便使用 join 操作关联多张表查询数据,但是经过分库分表后两张表可能都不在一个数据库中,如何使用 join 呢? 几种方案可以解决:
- 字段冗余:把需要关联的字段放入主表中,避免 join 操作;
- 数据抽象:通过ETL等将数据汇合聚集,生成新的表;
- 全局表:比如一些基础表可以在每个数据库中都放一份;
- 应用层组装:将基础数据查出来,通过应用程序计算组装;
分布式事务
单数据库可以用本地事务搞定,使用多数据库就只能通过分布式事务解决了。 常用解决方案有:基于可靠消息(MQ)的解决方案、两阶段事务提交、柔性事务等。
排序、分页、函数计算问题
在使用 SQL 时 order by, limit 等关键字需要特殊处理,一般来说采用分片的思路: 先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和 再次计算,最终得到结果。
分布式 ID
如果使用 Mysql 数据库在单库单表可以使用 id 自增作为主键,分库分表了之后就不行了,会出现id 重复。 常用的分布式 ID 解决方案有:
- UUID
- 基于数据库自增单独维护一张 ID表
- 雪花算法(Snowflake)
多数据源
分库分表之后可能会面临从多个数据库或多个子表中获取数据,一般的解决思路有:客户端适配和代理层适配。 业界常用的中间件有:
- shardingsphere(前身 sharding-jdbc)
- Mycat
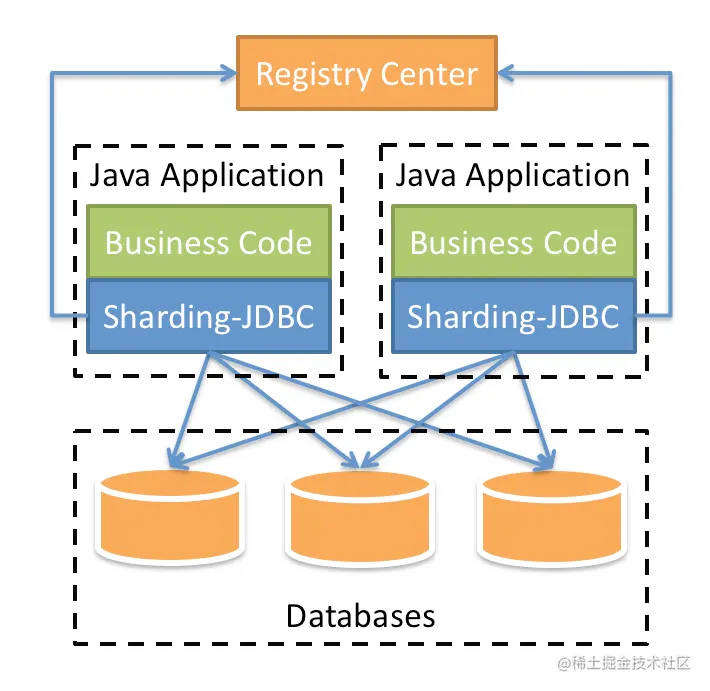
ShardingJdbc概览
shardingJdbc是什么
Sharding-JDBC 官网给出的解释是这样的:
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
shardingJdbc能干什么
- 数据分片:
- 读写分离
- 分库分表
- 分布式主键
- 分布式事务:
- XA强一致事务
- 柔性事务
- 数据库治理:
- 配置动态化
- 熔断&禁用
- 调用链路追踪
主从复制
原理
1) 当Master节点进行insert、update、delete操作时,会按顺序写入到binlog(二进制日志)中。 2) salve从库连接master主库,Master有多少个slave就会创建多少个binlog dump线程。 3) 当Master节点的binlog(二进制日志)发生变化时,binlog dump 线程会通知所有的salve节点,并将相应的binlog内容推送给slave节点。 4) I/O线程接收到 binlog 内容后,将内容写入到本地的 relay-log(中继日志)。 5) SQL线程读取I/O线程写入的relay-log,并且根据 relay-log 的内容对从数据库做对应的操作。
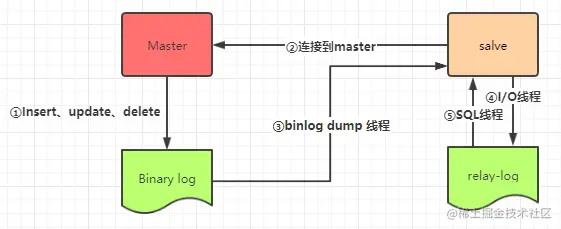
知道了主从复制的原理,我们也可以很清楚的知道,读写分离的写操作是必须要在master节点上进行,因为salve节点实现数据统一根据的是master节点的binlog, 我们如果在slave节点进行写操作,在master节点进行读操作,二者数据是不会统一的,主从复制也就失去的意义。
主实例搭建
- 修改mysql配置文件/etc/my.cnf
[mysqld] ## 设置server_id,同一局域网中需要唯一 server_id=11 ## 指定不需要同步的数据库名称 binlog-ignore-db=mysql ## 开启二进制日志功能 log-bin=mall-mysql-bin ## 设置二进制日志使用内存大小(事务) binlog_cache_size=1M ## 设置使用的二进制日志格式(mixed,statement,row) binlog_format=mixed ## 二进制日志过期清理时间。默认值为0,表示不自动清理。 expire_logs_days=7 ## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。 ## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致 slave_skip_errors=1062 - 修改完配置后重启实例:
service mysqld restart - 创建数据同步用户:
# 连接数据库 mysql -uroot -proot # 创建数据同步用户 # 为slave1创建同步账号 CREATE USER 'slave1'@'192.168.200.12' IDENTIFIED BY '123456'; GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave1'@'192.168.200.12'; # 为slave2创建同步账号 CREATE USER 'slave2'@'192.168.200.13' IDENTIFIED BY '123456'; GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave2'@'192.168.200.13';
从实例搭建
- 修改mysql配置文件/etc/my.cnf
[mysqld] ## 设置server_id,同一局域网中需要唯一 server_id=102 ## 指定不需要同步的数据库名称 binlog-ignore-db=mysql ## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用 log-bin=mall-mysql-slave1-bin ## 设置二进制日志使用内存大小(事务) binlog_cache_size=1M ## 设置使用的二进制日志格式(mixed,statement,row) binlog_format=mixed ## 二进制日志过期清理时间。默认值为0,表示不自动清理。 expire_logs_days=7 ## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。 ## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致 slave_skip_errors=1062 ## relay_log配置中继日志 relay_log=mall-mysql-relay-bin ## log_slave_updates表示slave将复制事件写进自己的二进制日志 log_slave_updates=1 ## slave设置为只读(具有super权限的用户除外) read_only=1 - 修改完配置后重启实例:
service mysqld restart
将主从数据库进行连接
- 连接到主数据库的mysql客户端,查看主数据库状态:
show master status; - 主数据库状态显示如下:

- 连接从数据库的mysql的客户端
mysql -uroot -proot - 在从数据库中配置主从复制:
change master to master_host='192.168.200.11', master_user='slave1', master_password='123456', master_port=3306, master_log_file='mall-mysql-bin.000001', master_log_pos=645, master_connect_retry=30; - 主从复制命令参数说明:
- master_host:主数据库的IP地址;
- master_port:主数据库的运行端口;
- master_user:在主数据库创建的用于同步数据的用户账号;
- master_password:在主数据库创建的用于同步数据的用户密码;
- master_log_file:指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数;
- master_log_pos:指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数;
- master_connect_retry:连接失败重试的时间间隔,单位为秒。
- 查看主从同步状态:
show slave status \G;*************************** 1. row *************************** Slave_IO_State: Master_Host: 192.168.200.11 Master_User: slave Master_Port: 3306 Connect_Retry: 30 Master_Log_File: mall-mysql-bin.000001 Read_Master_Log_Pos: 645 Relay_Log_File: mall-mysql-relay-bin.000001 Relay_Log_Pos: 4 Relay_Master_Log_File: mall-mysql-bin.000001 Slave_IO_Running: No #表示还没开始同步 Slave_SQL_Running: No #表示还没开始同步 Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 645 Relay_Log_Space: 154 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: NULL Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 0 Master_UUID: Master_Info_File: /var/lib/mysql/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: 1 row in set (0.00 sec) - 开启主从同步:
start slave; - 查看从数据库状态发现已经同步:
*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.200.11 Master_User: slave1 Master_Port: 3306 Connect_Retry: 30 Master_Log_File: mall-mysql-bin.000001 Read_Master_Log_Pos: 645 Relay_Log_File: mall-mysql-relay-bin.000002 Relay_Log_Pos: 325 Relay_Master_Log_File: mall-mysql-bin.000001 Slave_IO_Running: Yes # 同步成功 Slave_SQL_Running: Yes # 同步成功 Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 645 Relay_Log_Space: 537 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 11 Master_UUID: cabb05d9-d404-11eb-9530-000c299fd1be Master_Info_File: /var/lib/mysql/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: 1 row in set (0.00 sec)
主从复制测试
在主实例中创建一个数据库mall;在从实例中查看数据库,发现也有一个mall数据库,可以判断主从复制已经搭建成功。
读写分离
主从复制完成后,我们还需要实现读写分离,master负责写入数据,两台slave负责读取数据。怎么实现呢?
解决读写分离的方案有两种:应用层解决和中间件解决。
应用层解决
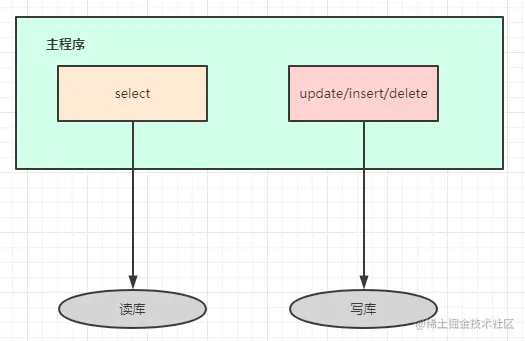
- 优点:
- 多数据源切换方便;
- 不需要引入中间件;
- 理论上支持任何数据库;
- 缺点:
- 由程序员完成,运维参与不到;
- 不能做到动态增加数据源;
中间件解决
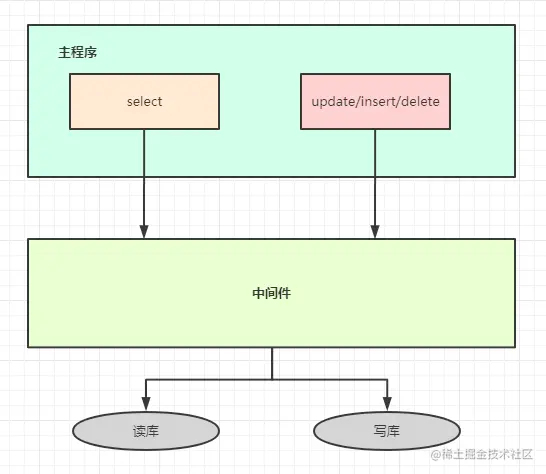
- 优点:
- 源程序不需要做任何改动就可以实现读写分离;
- 动态添加数据源不需要重启程序;
- 缺点:
- 程序依赖于中间件,会导致切换数据库变得困难;
- 由中间件做了中转代理,性能有所下降;
Sharding-Jdbc实现分库分表
版本说明
- SpringBoot:2.5.3
- druid:1.1.20
- mybatis-spring-boot-starter:1.3.2
- sharding-jdbc-spring-boot-starter:4.0.0-RC1
maven配置
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
application.yml配置
# 这是使用druid连接池的配置,其他的连接池配置可能有所不同
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: master,slave0,slave1
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.200.11:3306/mall?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
slave0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.200.12:3306/mall?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
slave1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.200.13:3306/mall?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
props:
sql.show: true
masterslave:
load-balance-algorithm-type: round_robin #round_robin random
sharding:
master-slave-rules:
master:
master-data-source-name: master
slave-data-source-names: slave1,slave0
sharding.master-slave-rules是标明主库和从库,一定不要写错,否则写入数据到从库,就会导致无法同步。 load-balance-algorithm-type是路由策略,round_robin表示轮询策略,random表示随机策略。 启动项目,可以看到以下信息,配置的三个数据源初始化,代表配置成功:

测试代码:
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import wang.cai2.shardingSphere.dao.CommodityMapper;
import wang.cai2.shardingSphere.entity.Commodity;
import java.util.List;
import java.util.Random;
/**
* @author wangpeixu
* @date 2021/8/12 13:56
*/
@SpringBootTest
public class masterTest {
@Autowired
private CommodityMapper commodityMapper;
@Test
void masterT() {
Commodity commodity = new Commodity();
commodity.setCommodityName("冬瓜");
commodity.setCommodityPrice("6");
commodity.setNumber(10000);
commodity.setDescription("卖冬瓜");
commodity.setId(String.valueOf(new Random().nextInt(1000)));
commodityMapper.addCommodity(commodity);
}
@Test
void queryTest() {
for (int i = 0; i < 10; i++) {
List<Commodity> query = commodityMapper.query();
System.out.println("-------");
}
}
}
插入数据masterT():  查询数据queryTest():
查询数据queryTest(): 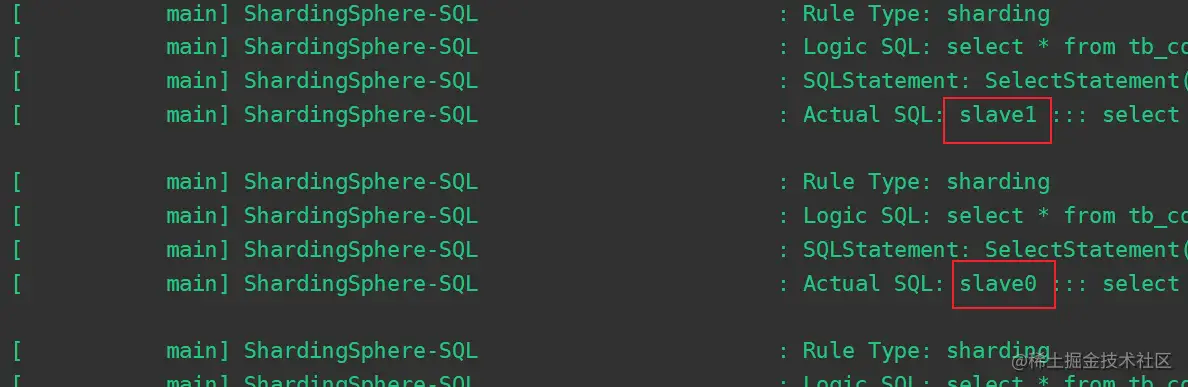
分库分表
配置文件如下:
# datasource
spring:
main:
allow-bean-definition-overriding: true
# 配置真实数据源
shardingsphere:
# 打开sql输出日志
props:
sql:
show: true
datasource:
names: db1,db2
# 第一个配置源
db1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/db_1?serverTimezone=UTC
username: root
password: root
# 第二个配置源
db2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/db_2?serverTimezone=UTC
username: root
password: root
sharding:
#库的分片策略
default-database-strategy:
inline:
sharding-column: user_id
algorithm-expression: db$->{user_id %2 +1}
tables:
course:
actual-data-nodes: db$->{1..2}.course_$->{1..2}
# 表的分片策略
table-strategy:
inline:
sharding-column: cid
algorithm-expression: course_$->{cid % 2 + 1}
# cid 的生成策略
key-generator:
column: cid
type: SNOWFLAKE #雪花算法
测试代码:
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import wang.cai2.shardingSphere.dao.CourseMapper;
import wang.cai2.shardingSphere.entity.Course;
import java.util.List;
@SpringBootTest
class ShardingSphereApplicationTests {
@Autowired
private CourseMapper courseMapper;
@Test
void saveCourse() {
for (int i = 1; i <= 10; i++) {
Course course = new Course();
course.setCname("java" + i);
course.setUserId(Long.valueOf(i));
course.setCstatus("Normal" + i);
courseMapper.saveCourse(course);
}
}
@Test
void findAll() {
List<Course> all = courseMapper.findAll();
for (Course course : all) {
System.out.println(course);
}
}
}
我们可以看到,数据是按照我们的配置插入了: 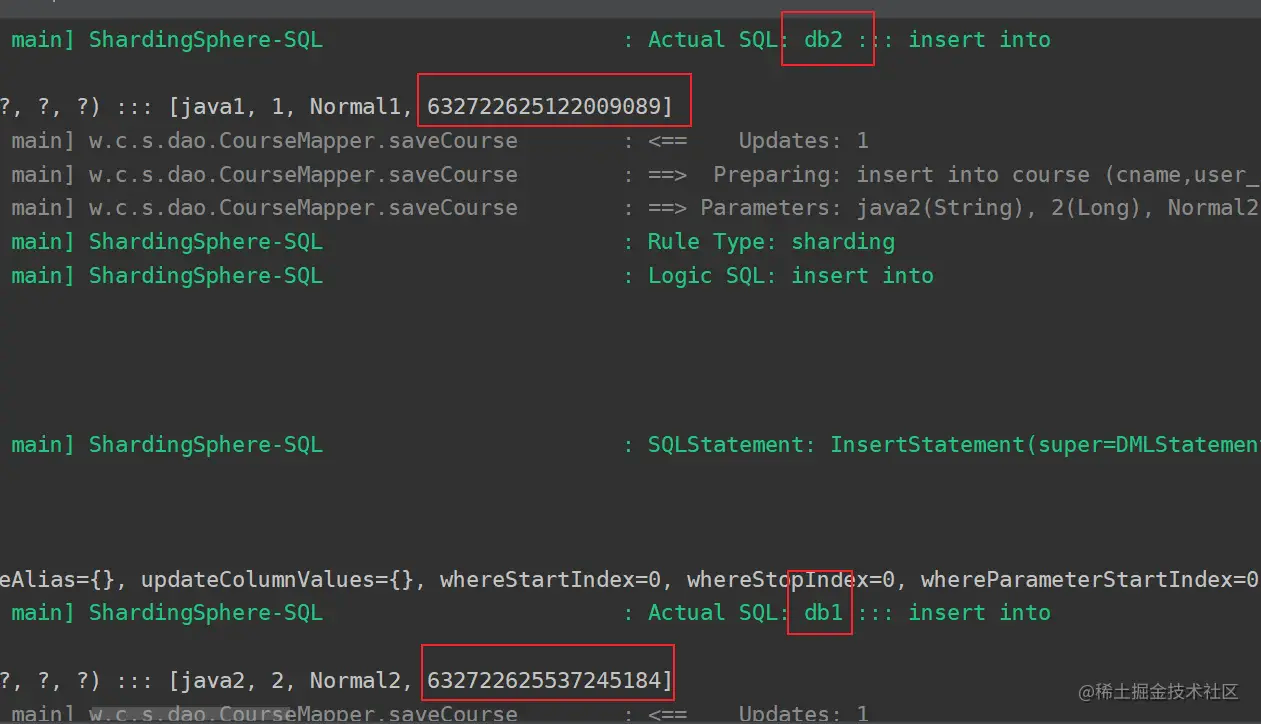
参考资料
- MySQL - ShardingJdbc 分库分表
- 手把手教你实现分库分表
- Sharding-JDBC的基本用法和基本原理
- MySQL - 一种简单易懂的 MyBatis 分库分表方案
- MySQL - 分表分库组件
文档信息
- 本文作者:Bob.Zhu
- 本文链接:https://adolphor.github.io/2023/08/09/02-shardingjdbc-for-mysql/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)