
Spark学习笔记。
MapReduce:计算框架和编程模型
计算机科学4大领域
- 系统领域
- 编程语言
- 人工智能
- 理论
其中,系统领域两大顶级会议:
- ODSI (USENIX conference on Operating Systems Design and Implementation)
- SOSP (ACM Symposium on Operating Systems Principles)
Google 的三驾马车
三篇论文:
- SOSP2003 分布式文件系统: The Google File System
- ODSI2004 分布式计算框架: MapReduce: Simplifed Data Processing on Large Clusters
- ODSI2006 分布式数据存储: Bigtable: A Distributed Storage System for Structured Data
MapReduce有两个含义:
- 计算框架 一般来说到计算框架时,指的是开源社区的 MapReduce 计算框架,随着新一代计算框架如 Spark、Flink 的崛起,开源社区的 MapReduce 计算框架在生产环境中使用得越来越少,逐渐退出舞台
- 编程模型 来源于古老的函数式编程思想,在Lisp 等比较老的语言中也有相应的实现,随着计算机 CPU 单核性能以及核心数量的飞速提升,MapReduce也在分布式计算中焕发出了新的生机
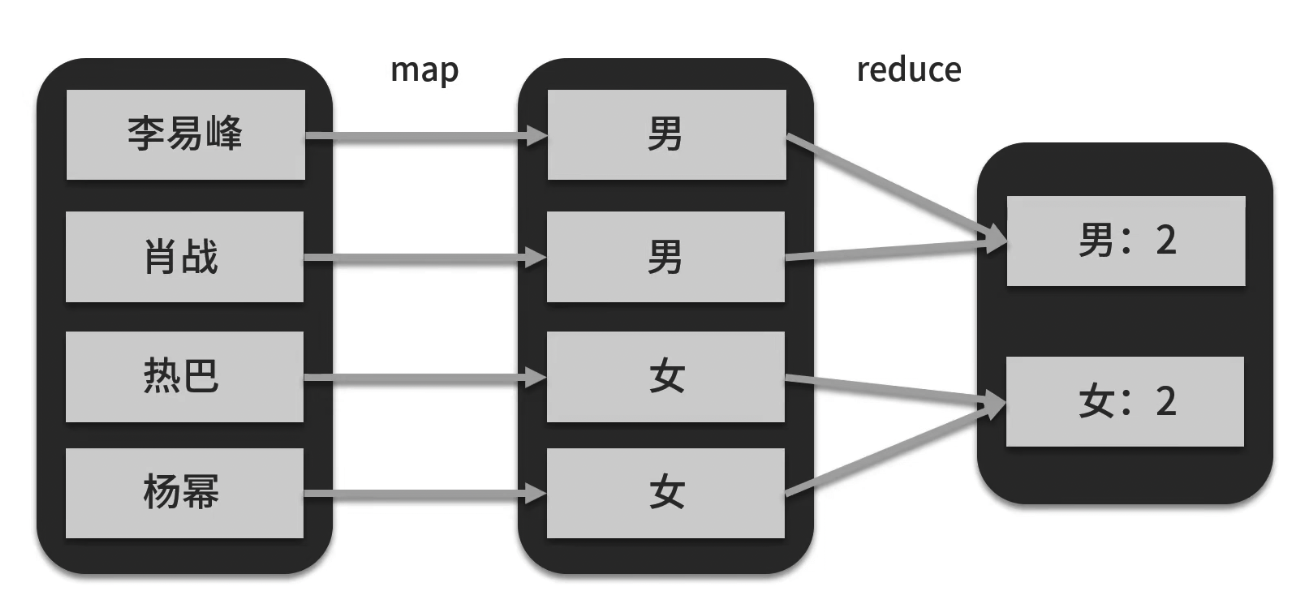
MapReduce计算过程:
- map:一对一,进行数据转换
- reduce:规约化简,进行数据聚合
Hadoop:集群的操作系统
Hadoop1.0
Hadoop1.0主要实现:
HDFS => MapReduce
在使用的过程中,这个架构还是会出现不少问题,主要有3点:
- 主节点可靠性差,没有热备
- 提交 MapReduce 作业过多的情况下,调度将成为整个分布式计算的瓶颈:没有将资源管理和作业调度这两个组件分开,当有多个作业的时候,资源调度器成为瓶颈
- 资源利用率低,并且不能支持其他类型的计算框架:资源调度器成为瓶颈后就造成资源的浪费,且因为主要是套用论文的实现,导致对其他类型的计算框架的兼容性差
Hadoop2.0
Hadoop2.0 主要改进:
- YARN 将集群内的所有计算资源抽象成一个资源池,资源池的维度有两个:CPU、内存
- 基于 HDFS,可以认为 YARN 管理计算资源,HDFS 管理存储资源;HDFS也变成了很多系统的底层存储
- 上层的计算框架地位也大大降低,变成了 YARN 的一个用户:兼容多个计算框架,如Spark、Storm、MapReduce等
- 另外,YARN 采取了双层调度的设计,大大减轻了调度器的负担
Hadoop 以一种兼收并蓄的态度网罗了一大批大数据开源技术组件,逐渐形成了一个庞大的生态圈,这也是广义的Hadoop的概念。
Hadoop生态圈与发行版
Hadoop 生态圈的各个组件包含了:
- Hadoop 的核心组件,如 HDFS、YARN;
- 在计算层也有了更多的选择,如支持 SQL的Hive、lmpala, 以及Pig、Spark. Storm等。
- 负责批量数据抽取的 Sqoop,负责流式数据传输的 Flume,负责分布式一致性的 Zookeeper
- 一些运维类组件,例如负责部署的 Ambari、集群监控的 ganglia 等
看似繁杂,但都是一个生产环境的所必需的。
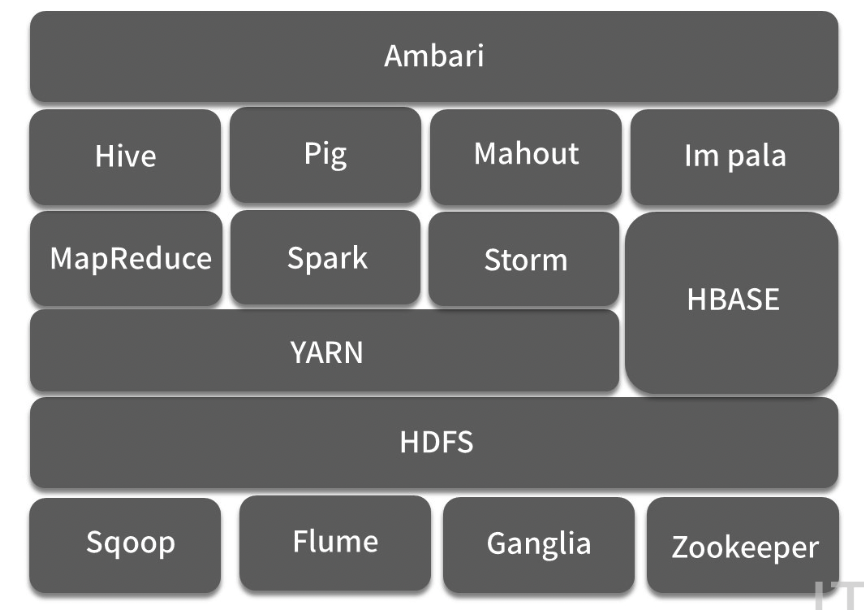
Hadoop大数据平台
Hadoop 可以理解为是一个计算机集群的操作系统, 而 Spark、MapReduce 只是这个操作系统支持的编程语言而已。 HDFS 是基于所有计算机文件系统之上的文件系统抽象。
Hadoop 是基于所有计算机的操作系统之上的操作系统抽象, YARN 是基于所有计算机资源管理与调度系统之上的资源管理与调度系统抽象, 如果一定要进行比较的话,Hadoop 应该和操作系统相比较
Hadoop趋势
随着计算框架的发展,Hadoop存在感越来越低,在大数据平台底层,有些大数据甚至只采用HDFS, 其余都按照需求选择其他技术组件。还有一些计算框架自带生态,比如Spark的BDAS,这就造成了 一种现象:Hadoop的热度越来越低,而分布式计算框架的热度越来越高。就像Java的热度肯定比Linux高, 这也符合计算机的发展规律。
如何设计与实现统一资源管理与调度系统
Hadoop 2.0与Hadoop 1.0 最大的变化是引入了 YARN,Spark 在很多情况下,也是基于 YARN 运行, YARN 承担着计算资源管理与调度的工作。 主要内容:
- 统一资源管理与调度系统的设计
- 统一资源管理与调度系统的实现 —— YARN
设计
YARN 全称是 Yet Another Resource Negotiator。 直译:另一种资源协调者;标准名称:统一资源管理与调度系统
逐词解释:
- 统一:资源不与计算框架绑定
- 资源管理:资源维度,CPU和内存
- 调度系统:
- 集中式调度器:Monolithic Scheduler,只有一个中央调度器,实际利用率只有70%左右,甚至更低
- 双层调度器:Two-Level Scheduler,中央调度器和框架调度器,中央调度器将资源粗力度分配给框架调度器,再由框架调度器细分任务给容器中的计算任务
- 状态共享调度器:Shared-State Scheduler,是由GOogle的Omega调度系统所提出的一种新范式。
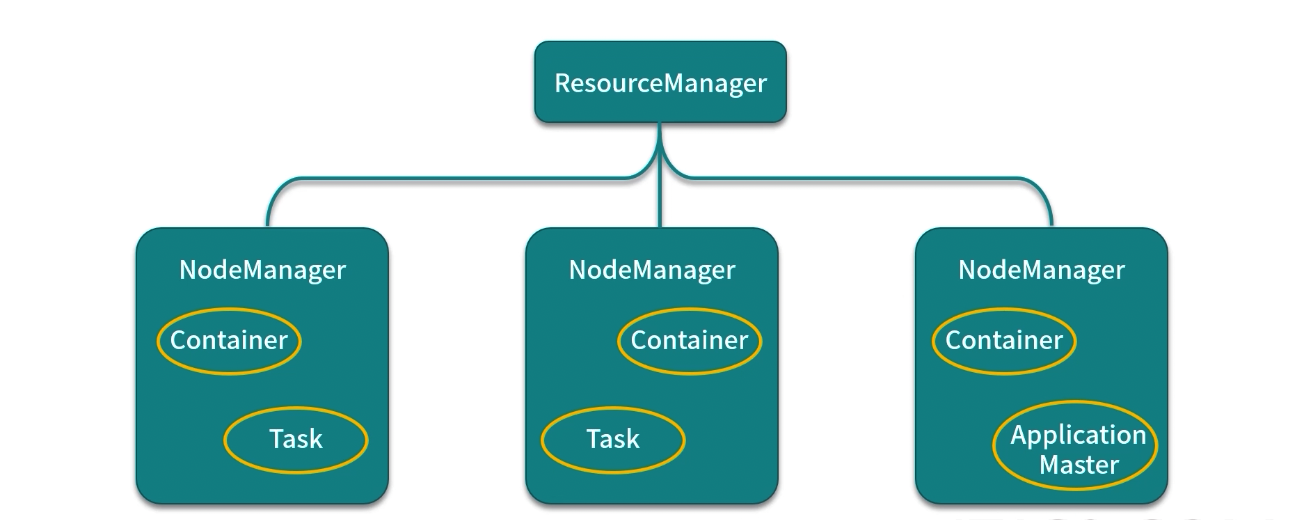
实现:YARN
YARN架构图
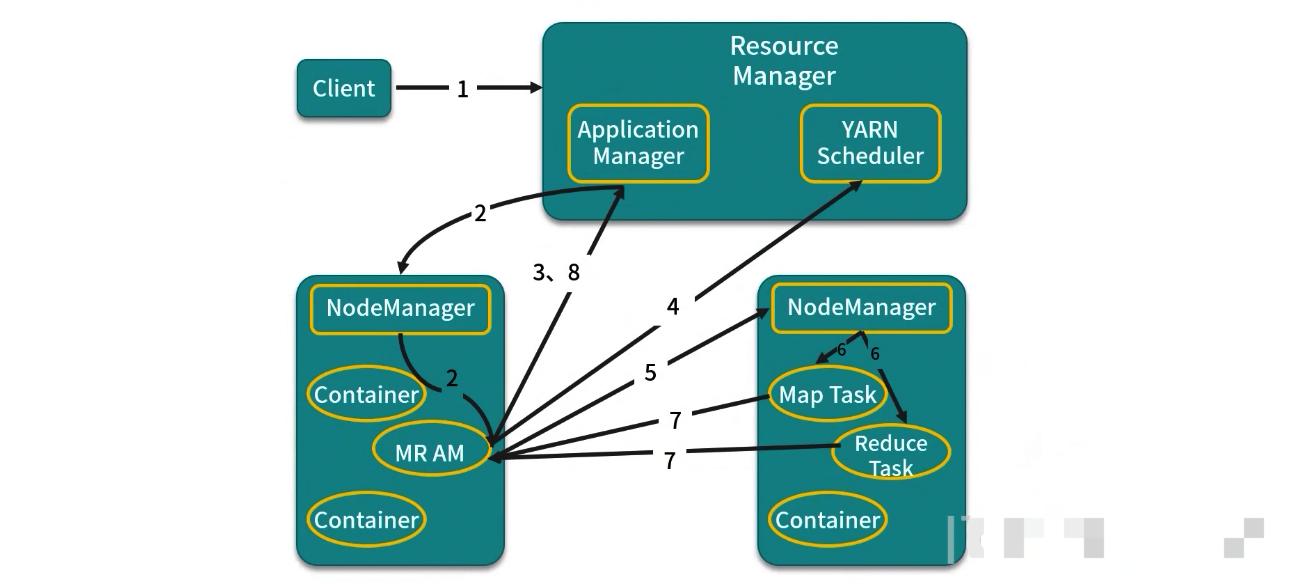
YARN作业流程
解析Spark数据处理与场景分析
不同纬度下的场景分析(可能会有重合部分):
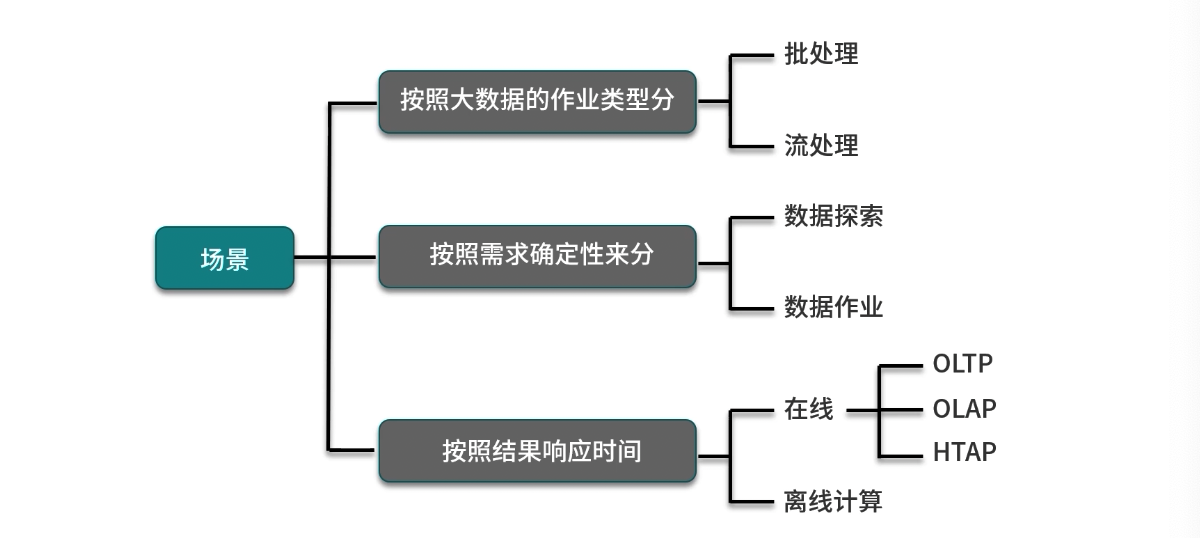
如何选择Spark编程语言以及部署Spark
Spark编程语言
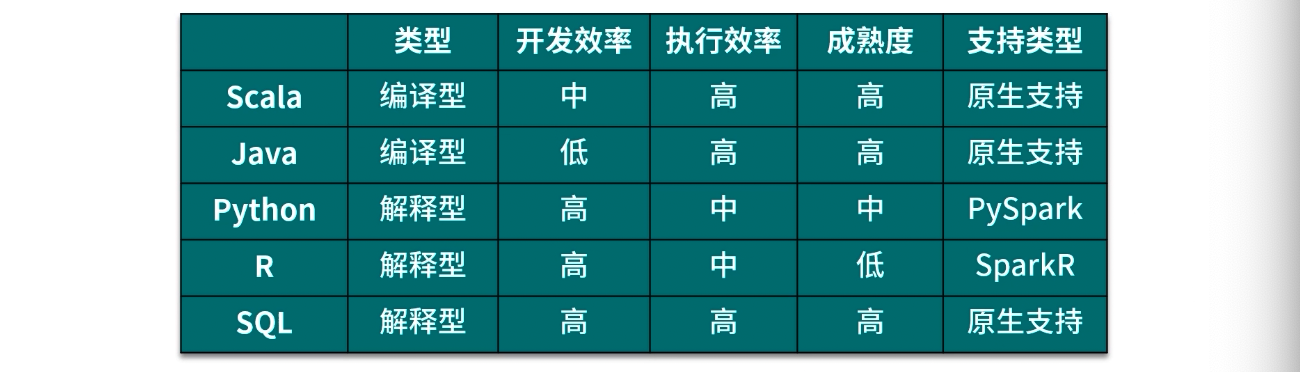
如果从零开始,建议在Scala和Python中间选择。
部署Spark
Spark 支持的统一资源管理与调度系统有:
- Spark standalone:缺点多,不建议
- YARN:
- Mesos:最早支持的平台
- Kubernetes:最新的Spark2.4.5才支持
- 本地操作系统:
安装Spark学习环境
介绍了PySpark方式。
Spark抽象、架构与运行环境
Spark具体技术模块的内容:
- Spark背后的工程实现
- Spark的基础编程接口
Spark架构
- 在生产环境中,Spark往往作为统一资源管理平台的用户向统一资源管理平台提交作业,作业提交成功后,Spark 的作业会被调度成计算任务,在资源管理系统的容器中运行
- 在集群运行中的 Spark 架构是典型的主从架构
- 所有分布式架构无外乎两种:
- 一种是主从架构 (master/slave)
- 另一种是点对点架构 (p2p)
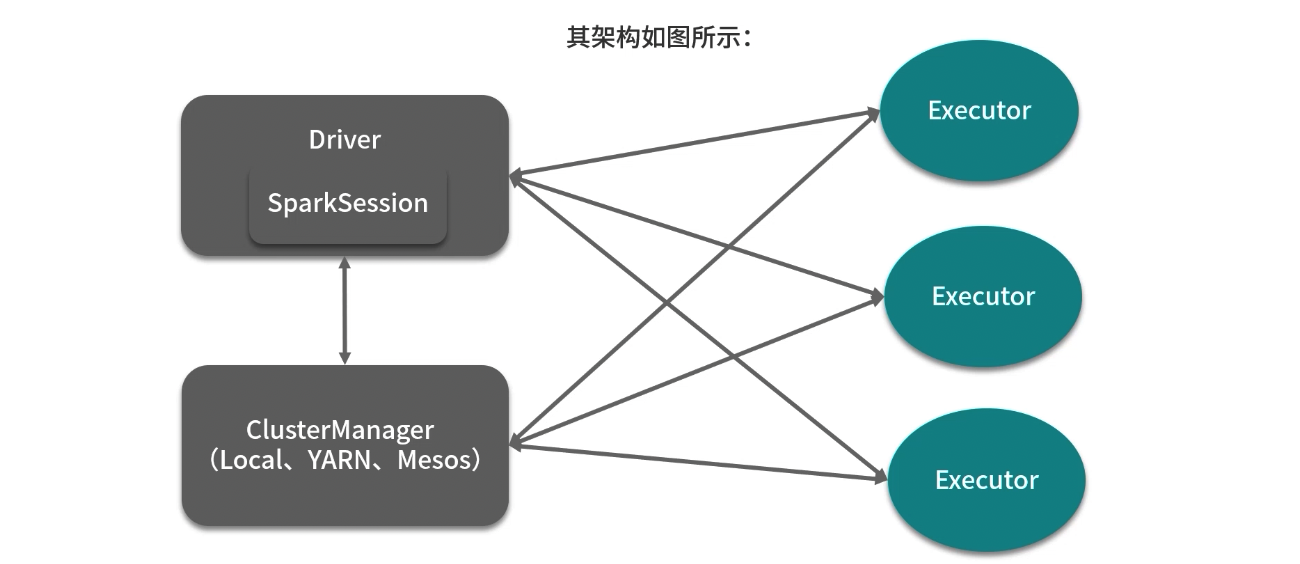
主要组件:
- 在Spark 的架构中,Driver 主要负责作业调度工
- Executor 主要负责执行具体的作业计算任务
详细解释:
- Driver 中的SparkSession 组件是 Spark 2.0 引入的一个新的组件,曾经我们熱悉的 SparkContext、SqlContext、HiveContext 都是 SparkSession 的成员变量
- 用户编写的 Spark 代码是从新建 SparkSession 开始
- 其中 SparkContext 的作用: 连接用户编写的代码与运行作业调度以及任务分发的代码
- 当用户提交作业启动一个Driver 时,会通过 SparkContext 向集群发送命令,Executor 会遵照指令执行任务
- 一旦整个执行过程完成,Driver 就会结束整个作业
Spark抽象
Spark运行环境
参考资料
开始写作吧

文档信息
- 本文作者:Bob.Zhu
- 本文链接:https://adolphor.github.io/2023/08/14/01-study-practice-spark-in-action/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)